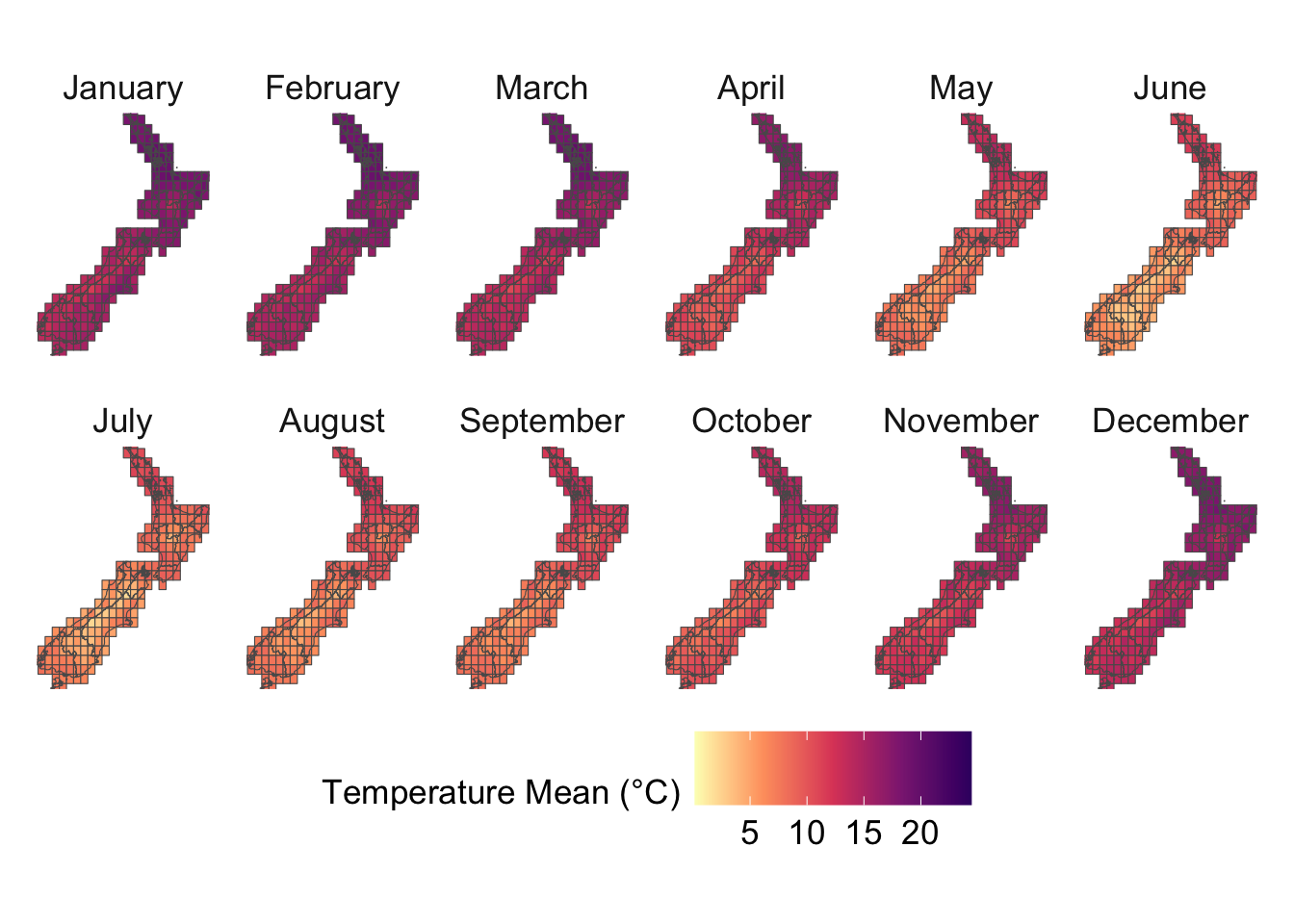
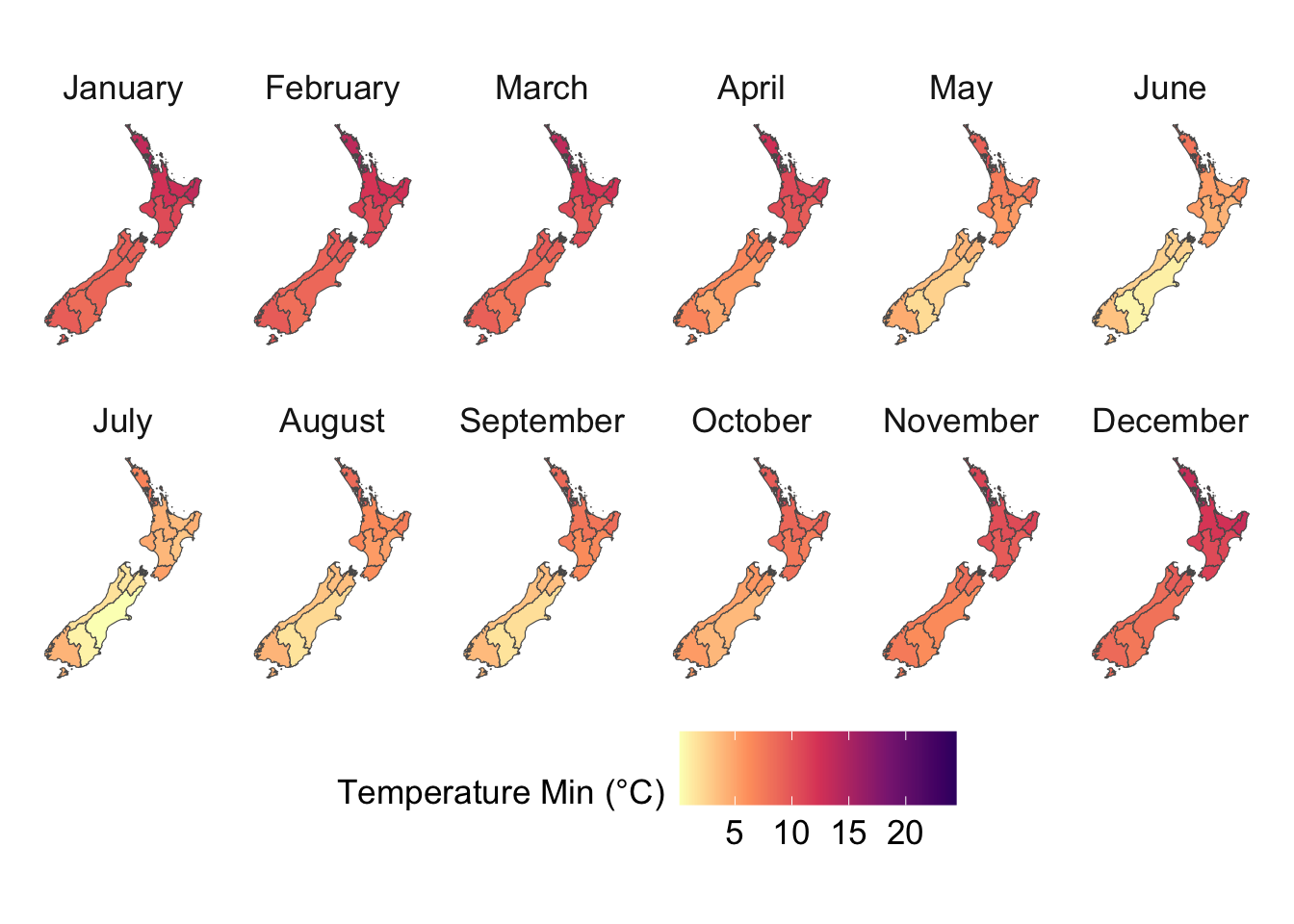
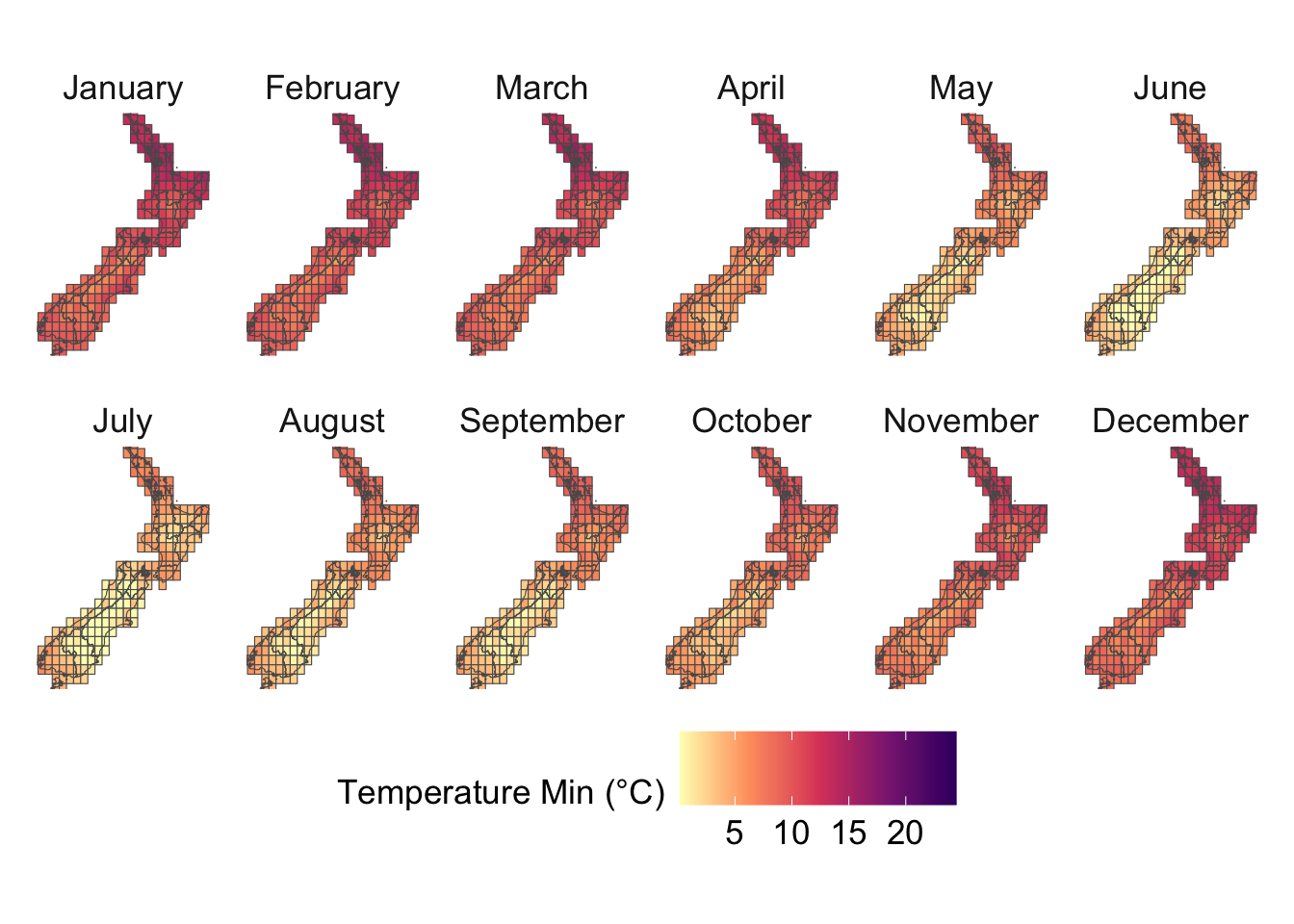
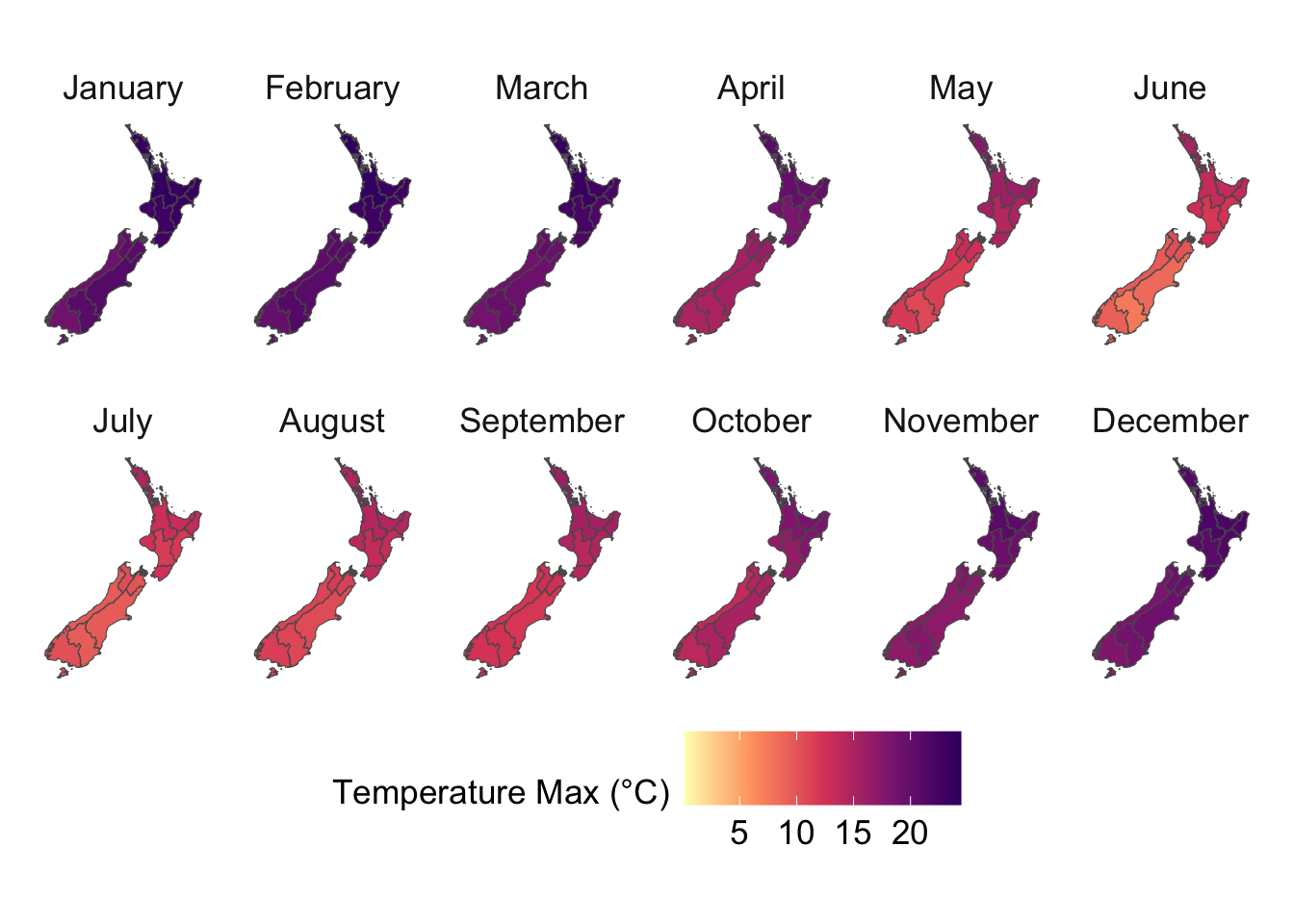
This chapter uses the gridded weather data from Chapter 4 to construct various metrics. Please refer to the 27 core ETCCDI Climate Change Indices (https://etccdi.pacificclimate.org/indices.shtml) for additional metrics that can be constructed.
All these metrics will be computed at the grid cell level, on the finest temporal scale. Aggregation at various levels (monthly, quarterly) to match with macroeconomic data will be performed once the indicators are created. Spatial aggregation will not be performed in this chapter.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.2
✔ ggplot2 4.0.0 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(sf)
Linking to GEOS 3.13.0, GDAL 3.8.5, PROJ 9.5.1; sf_use_s2() is TRUE
library(scales)
Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
library(zoo)
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
library(lubridate)
Let us load the graphs theme functions (See Chapter 1):
source("../scripts/functions/utils.R")
Let us also load the maps for the countries of interest (See Chapter 2)
We have daily precipitation \(P_t\), minimum temperatures \(\text{Tmin}_{t}\) and maximum temperatures \(\text{Tmax}_{t}\) at the grid cell level. We are interested in building a soil moisture index which requires to compute the evapotranspiration in a prior step. We follow the approach presented in Dingman (2015) (pp. 299–300, Box 6.8: Thornthwaite-Type Monthly Water-Balance Model) and recalled in Appendix S1 of Lutz, Wagtendonk, and Franklin (2010).
5.1.1 Potential Evapotranspiration
The daily PET (in mm/day) writes (assumed to be from Hamon (1964), but the article cannot be found on the Internet ; Dingman (2015) Eq. 6.68 p. 294): \[
\text{PET}_t =
\begin{cases}
0, & \text{if }\mathrm{Tmean}_t \le 0^\circ\mathrm{C},\\
29.8 \times \text{DL}_t \times \dfrac{e^\star(\mathrm{Tmean}_t)}{\mathrm{Tmean}_t + 273.2}, & \mathrm{otherwise},
\end{cases}
\tag{5.1}\]
where \(\text{DL}_t\) is the day length of day \(t\), expressed in hours and \(e^\star(\cdot)\) gives the saturation vapour pressure.
\(\text{Tmean}_t\) is the daily average temperature: \[
\mathrm{Tmean}_t = \frac{\mathrm{Tmin}_t + \mathrm{Tmax}_t}{2}.
\tag{5.2}\]
How to compute day length \(\text{DL}_t\)?
The methodology to compute day length is given in Appendix D of Dingman (2015). It writes:
where \(\omega_s\) (in radians) is the sunrise hour angle. At sunrise and sunset, the solar zenith angle \(\theta_z\) equals \(90^\circ + h_0\), where \(h_0\) is the apparent altitude of the Sun’s center at sunrise. The sunrise hour angle \(\omega_s\) satisfies: \[
\cos(\omega_s) = \dfrac{\sin(h_0) - \sin(\Lambda) \sin(\delta)}{\cos(\Lambda) \cos(\delta)},
\tag{5.4}\] with \(\Lambda\) the latitude (in radians), \(\delta\) the solar declination (in radians) and \(h_0 \approx -0.833^\circ\).
The solar declination in radians writes (Campbell and Norman (1998)): \[
\sin^{-1}(0.39795 \times \cos(0.2163108 + 2 \tan^{-1}(0.9671396 \times \tan(0.0086 \times (\text{doy}_t - 186))) ))
\tag{5.5}\]
How to compute saturation vapour pressure \(e^\star(T)\)?
The saturation vapour pressure \(e^\star(\cdot)\) (in k pascals) is given, for a temperature \(T\) (in °C), by (Dingman (2015), Box 2.2 p.99): \[
e^\star(T) = 0.611 \exp\left(\frac{17.27\times T}{T + 237.3}\right)
\tag{5.6}\]
Let us compute the daily potential evapotranspiration in R. We define two functions:
decl_angle(), which computes the solar declination in radians for a given day-of-year (the code is from {TrenchR}),
daylength_hours(), which computes the day length (in hours) for a given day-of-year, at a given latitude.
The decl_angle() function.
#' @title Solar Declination in Radians (from {TrenchR})#' #' @description The function calculates solar declination, which is the angular #' distance of the sun north or south of the earth's equator, based on the day #' of year (Campbell and Norman, 1998)#' #' @param doy Day of year (1-366).#' #' @returns The declination angle (in radians).#'#' @references#' Campbell GS, Norman JM (1998). Introduction to environmental biophysics, #' 2nd ed. edition. Springer, New York. ISBN 0387949372.decl_angle <-function (doy) { doy <- (doy -1) %%365+1 rev_ang <-0.2163108+2*atan(0.9671396*tan(0.0086* (doy -186))) asin(0.39795*cos(rev_ang)) }
The daylength_hours() function.
#' Day length (in hours)#' #' @param lat_deg Latitude (in degrees)#' @param doy Day of year (1-366).#' daylength_hours <-function(lat_deg, doy) { lambda <- lat_deg * pi /180 delta <-decl_angle(doy) h0 <--0.833* pi /180# apparent sunrise altitude# General sunrise equation with altitude:# cos(ws) = (sin(h0) - sin(lambda) sin(delta)) / (cos(lambda) cos(delta)) num <-sin(h0) -sin(lambda) *sin(delta) den <-cos(lambda) *cos(delta) cos_ws <- num / den cos_ws <-pmin(pmax(cos_ws, -1), 1) # clamp to [-1,1] ws <-acos(cos_ws) (24/pi) * ws}
The equation for soil water balance depends on whether water input (\(W_t\)) exceeds potential evapostranspiration (Lutz, Wagtendonk, and Franklin (2010)):
where \(\Delta_{\text{soil},t}\) is the fraction removed from storage: \[
\Delta_{\text{soil},t} = \text{SW}_{t-1} \times\left( 1 - \exp\left(-\dfrac{\text{PET}_t - W_t}{S_\text{max}}\right)\right),
\tag{5.8}\]
\(S_{\text{max}}\) is the soil water-holding capacity in the top 200 cm of the soil profile. Ideally, this should be given from recorded values. We do not have this here, so we will use a value of 150mm:
The current NIWA water balance model uses a fixed soil moisture capacity of 150 mm of water, based on a typical loam soil. https://niwa.co.nz/sites/default/files/NZDI_more_info.pdf (New Zealand Drought Index and Drought Monitor Framework).
The deficit writes: \[
D_t = \text{PET}_t - \text{AET}_t.
\]
How to compute water input \(W_t\) with daily data?
Daily snowmelt is often estimated using a degree-day approach, which assumes that melt is proportional to the number of degrees by which air temperature exceeds a threshold (typically 0°C). This formulation applies only to the existing snowpack, ensuring that snow deposited on a given day cannot melt immediately.
Following the standard degree-day formulation (Dingman (2015), Eq. 5.71), the daily snowmelt is written as a linear function of air temperature: \[
\text{Melt}_t = \min\left\{\text{DDF} \times \max(\mathrm{Tmean}_t - T_0,\, 0),\, \text{Pack}_{t-1}\right\}
\tag{5.9}\]
where \(\text{DDF}\) is the degree-day factor (mm day\(^{-1}\)°C\(^{-1}\)), typically in the range 2–5 mm day\(^{-1}\)°C\(^{-1}\) depending on snow properties and surface conditions. The parameter \(T_0\) is the threshold temperature for melting (which is always set as 0°C). \(\mathrm{Tmean}_t\) is the daily mean air temperature (see Equation 5.13). \(\text{Pack}_{t-1}\) is the snow water equivalent remaining from the previous day.
The snowpack evolves according to the mass balance: \[
\text{Pack}_t = \text{Pack}_{t-1} + \text{Snow}_t - \text{Melt}_t.
\]
The snow pack equation is recursive. We simply set the start value at 0 for the first date of the sequence of values within a cell.
\(\text{Snow}_t\) is the amount of snow, which is the amount of precipitation if the average daily temperature is lower or equal to \(T_0\), and 0 otherwise: \[
\text{Snow}_t = \begin{cases}
P_t, & \text{if } T_{\text{mean}_t} \leq T_0 \\
0, & \text{otherwise}.
\end{cases}
\tag{5.10}\]
Conversely, the amount of rain is defined as: \[
\text{Rain}_t = \begin{cases}
P_t, & \text{if } T_{\text{mean}_t} > T_0 \\
0, & \text{otherwise}.
\end{cases}
\tag{5.11}\]
The total water input to the soil becomes: \[
W_t = \text{Rain}_t + \text{Melt}_t.
\]
How to compute water input \(W_t\) with monthly data?
Melt Factor and Rain/Snow Partition
The monthly precipitation can be divided into a rain fraction \(\text{Rain}_t\) and a snow fraction \(\text{Snow}_t\). To do so, we define the melt factor \(F_t\): \[
F_t = \begin{cases}
0, & \text{if }\text{Tmean}_t \leq 0^\circ,\\
0.167 \times \text{Tmean}_t, & \text{if } 0^\circ <\text{Tmean}_t \leq 6^\circ,\\
0, & \text{if }\text{Tmean}_t > 6^\circ.
\end{cases}
\tag{5.12}\]
where \(\text{Tmean}_t\) is the daily average temperature: \[
\mathrm{Tmean}_t = \frac{\mathrm{Tmin}_t + \mathrm{Tmax}_t}{2}.
\tag{5.13}\]
The rain and snow fractions can then be computed as follows: \[
\begin{align}
\text{Rain}_t & = F_t \times P_t\\
\text{Snow}_t & = (1 - F_t) \times P_t
\end{align}
\tag{5.14}\]
Recursive Snowpack and Melt
The melt factor \(F_t\) is also used to define snowmelt \(\text{Melt}_t\): \[
\text{Melt}_t = F_t \times (\text{Snow}_t + \text{Pack}_{t-1}),
\tag{5.15}\]
where snow pack for a given day is given by: \[
\text{Pack}_t = (1 - F_t)^2 \times P_t + (1 - F_t) \times \text{Pack}_{t-1}
\tag{5.16}\]
The snow pack equation is recursive. We simply set the start value at 0 for the first date of the sequence of values within a cell.
The monthly water input to the soil is obtained as: \[
W_t = \text{Rain}_t + \text{Melt}_t
\tag{5.17}\]
# This code is not evaluated here since we use daily datacountry_weather_daily <- country_weather_daily |>mutate(# Monthly melt factor and rain/snow splitmelt_factor =case_when( temp_mean <=0~0, temp_mean >=6~1,TRUE~0.167* temp_mean ),rain = melt_factor * precip,snow = (1- melt_factor) * precip ) |>arrange(cell_id, date) |>group_by(cell_id) |># Monthly snowpack recursion and meltmutate(a =1- melt_factor,b = (a^2) * precip, # term added each dayc = a, # multiplier on previous packpack = { init <-0# initial PACK for this cell_id# pack_t = b_t + c_t * pack_{t-1} out <- purrr:::accumulate2( b, c,.init = init,.f =function(bi, ci, prev) bi + ci * prev )as.numeric(tail(out, -1)) # drop the initial value },pack_lag =lag(pack, default =0),melt = melt_factor * (snow + pack_lag),water_input = rain + melt ) |>ungroup() |>select(-a, -b, -c)
Then, we can compute soil water balance (\(\text{SW}_t\)), actual evapotranspiration (\(\text{AET}_t\)) and soil water deficit \(D_t\).
We define the update_soil_water_deficit() function that computes those values for a subset of observation corresponding to a cell, using the following input variables: \(W_t\), \(\text{PET}_t\), \(\text{SW}_{t-1}\) and \(S_{\text{max}}\).
The update_soil_water_deficit() function.
#' Compute Soil Water Deficit#' #' @param W Water input to the system (in mm).#' @param PET Potential evapotranspiration (in mm).#' @param S_prev Soil water balance in previous period (in mm).#' @param S_max Soil water-holding capacity in the top 200cm of the soil #' profile (in mm).#' #' @returns A list with the following elements:#' - `S_new`: soil water balance,#' - `AET`: evapotranspiration,#' - `surplus`: water surplus,#' - `deficit`: water deficit#' update_soil_water_deficit <-function(W, PET, S_prev, S_max) {if (W >= PET) {# Water-abundant day: recharge first, overflow = surplus S_star <- (W - PET) + S_prev# New value for soil water balance S_new <-min(S_star, S_max) AET <- PET # Evapotranspiration surplus <-max(0, S_star - S_max) deficit <-0 } else {# Water-limited day: exponential draw from storage (Dingman/Lutz Eq. 13) D <- PET - W # unmet demand by inputs dSOIL <- S_prev * (1-exp(-D / S_max)) # fraction removed from storage# New value for soil water balance S_new <- S_prev - dSOIL AET <- W + dSOIL # Evapotranspiration surplus <-0 deficit <- PET - AET }list(S_new = S_new, # Soil water balanceAET = AET, # Evapotranspirationsurplus = surplus, # Water surplusdeficit = deficit # Water deficit )}
We use that function on subsets of the dataset where each subset corresponds to a cell.
# Note: this chunk takes about 3 minutes to run.# It is not evaluated here during compilation.if (!file.exists("NZL_temprary_water_deficit.rda")) {# Ideally, we would need to use a value at the cell level. Smax_default <-150 country_weather_daily <- country_weather_daily |>arrange(cell_id, date) |>group_by(cell_id) |># Prepare new columnsmutate(AET =NA_real_, # Evapostranspirationsoil_moisture =NA_real_, # Water storagesoil_surplus =NA_real_, # Water surplussoil_deficit =NA_real_# Water deficit ) |># For each cell, compute soil water deficit recursivelygroup_modify(\(tb, key){ n <-nrow(tb) S <-0.5* Smax_defaultfor (i inseq_len(n)) { u <-update_soil_water_deficit(W = tb$water_input[i],PET = tb$PET_daily[i],S_prev = S,S_max = Smax_default ) tb$AET[i] <- u$AET tb$soil_moisture[i] <- u$S_new tb$soil_surplus[i] <- u$surplus tb$soil_deficit[i] <- u$deficit S <- u$S_new } tb }) |>ungroup()save( country_weather_daily, file ="NZL_temprary_water_deficit.rda" )} else {load("NZL_temprary_water_deficit.rda")}country_weather_daily
The Soil Moisture Deficit Index (SMDI, see Narasimhan and Srinivasan (2005)), turns daily soil water storage into a weekly drought/wetness index which takes values on \([-4,4]\) and which is comparable across locations and seasons. Negative values indicate dry conditions whereas positive values indicate wet conditions.
Since we have daily observation, we need to compute weekly values for soil moisture. We assign each day to one of 52 fixed 7-day blocks starting on January 1: \[
\text{week} = \min\left(\left\lfloor\frac{\text{yday}-1}{7}\right\rfloor + 1,\ 52\right).
\] Note that we do not use the week() function from {lubridate} to avoid ISO weeks (which can have 53).
Then, for each grid cell (i), year (y), and week (w), compute the weekly mean available soil water: \[
\mathrm{SW}_{i,y,w} = \frac{1}{n_{i,y,w}} \sum_{t \in (i,y,w)} \text{SW}_t,
\tag{5.18}\]
where \(\text{SW}_t\) is the soil water balance (in mm), previously computed (see Equation 5.7).
We define a function, find_wday() which assigns a fixed 7-day “week” indice (1 to 52) to calendar dates.
#' Assign fixed 7-day "week" indices (1–52) to calendar dates#'#' @description#' Divides each year into 52 fixed 7-day blocks, starting on January 1#' (block 1 = days 1–7, block 2 = days 8–14, ...#' Any remaining day(s) beyond day 364 (e.g., Dec 31 in common years,#' or Dec 30–31 in leap years) are assigned to week 52.#'#' @param x A `Date` vector.#' @returns#' An integer vector of the same length as `x`, giving week indices in `1:52`.#' find_wday <-function(x) {pmin(((yday(x) -1) %/%7) +1, 52)}
# First assign each day to one of the 52 weekscountry_weather_daily <- country_weather_daily |>mutate(# week = lubridate::week(date) # includes 53...week =find_wday(date) )# Then compute the average availabe soil water at the cell levelsw_weekly <- country_weather_daily |>group_by(cell_id, year, week) |>summarise(SW =mean(soil_moisture, na.rm =TRUE), .groups ="drop")
The long-term weekly statistics at the cell level then need to be computed:
\(\text{MSW}_{i,w}\): the median of \(\text{SW}_{i,y,w}\) over a long period (the entire sample, here),
\(\text{SW}_{\text{min},i,w}\): the min of \(\text{SW}_{i,y,w}\) over the same long period.
\(\text{SW}_{\text{max},i,w}\): the max of \(\text{SW}_{i,y,w}\) over the same long period.
The weekly soil-water anomaly are then computed, in percent. For each (cell, year, week), a piecewise, range-normalized anomaly is computed as follows: \[
\text{SD}_{i,y,w} =
\begin{cases}
100 \dfrac{\text{SW}_{i,y,w} - \text{MSW}_{i,w}}{\text{MSW}_{i,w}-\text{SW}_{\min,i,w}}, & \text{if } \text{SW}_{i,y,w} \le \text{MSW}_{i,w},\\
100 \dfrac{\text{SW}_{i,y,w} - \text{MSW}_{i,w}}{\text{SW}_{\max,i,w}-\mathrm{MSW}_{i,w}}, & \text{otherwise}
\end{cases}
\tag{5.19}\]
Weekly soil water anomalies \(\text{SD}_{i,y,w}\) will be negative when they are drier than the median for that week, positive when wetter, and naturally scaled by the local weekly climatological range.
You may have notice that in the previous code, the denominator is ‘protected’ with a tiny value (\(10^{-9}\)) to avoid division by zero in flat climates.
The last step consists in computing the SMDI in a recursive manner: the SMDI carries persistence via a first-order recursion within each calendar year: \[
\begin{align*}
\text{SMDI}_{i,y,1} & = \frac{\text{SD}_{i,y,1}}{50},\\
\text{SMDI}_{i,y,w} & = 0.5,\text{SMDI}_{i,y,w-1} + \frac{\text{SD}_{i,y,w}}{50}\quad (w\ge 2).
\end{align*}
\tag{5.20}\]
# SMDI computed recursively, by cell.smdi_weekly <- sw_anom |>arrange(cell_id, year, week) |>group_by(cell_id, year) |>group_modify(\(tb, key) { n <-nrow(tb) smdi <-numeric(n)for (i inseq_len(n)) {if (i ==1||is.na(smdi[i-1])) {# Initial value smdi[i] <- tb$SD[i] /50 } else { smdi[i] <-0.5* smdi[i-1] + tb$SD[i] /50 } } tb$SMDI <- smdi tb }) |>ungroup()
Let us have a look at the values for a cell:
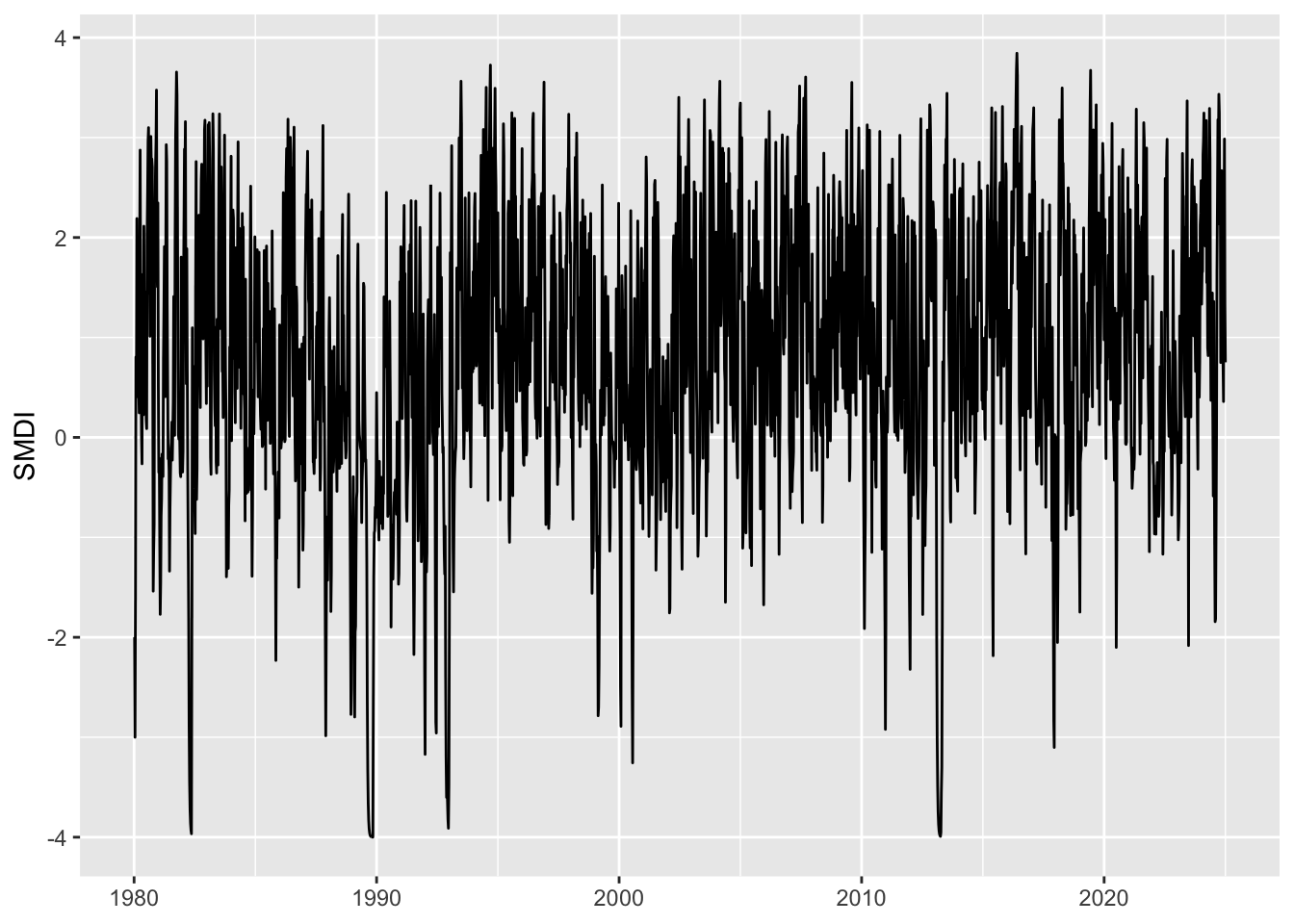
ggplot(data = smdi_weekly |>filter(cell_id ==19) |>mutate(x = year + week/52),mapping =aes(x = x, y = SMDI)) +geom_line() +labs(x =NULL)
Figure 5.1: SMDI for a cell in New Zealand. Weekly values range from -4 to +4 indicating very dry to very wet conditions.
5.3.1 Monthly Aggregation
The SMDI values are computed on a weekly basis (52 fixed 7-day blocks per year). To align with standard reporting periods of macroeconomic data, we can aggregate these values to the monthly scale. Because some 7-day weeks span two months, we need to ensure that each month receives only the appropriate share of each week.
We proceed as follows:
We build a monthly calendar of overlaps. For every combination of year and month present in the data, we compute how many days of each fixed 7-day week fall within that month. This gives us a set of weights (\(w^{(m)}_{w}\)) that indicate the fraction of the month covered by each week. The weights for a given month always sum to 1.
We compute weighted monthly SMDI values. We join the weights from the previous step with the weekly SMDI observations and compute, for each grid cell, year, and month, a weighted mean of weekly SMDI values: \[
\mathrm{SMDI}_{m} = \frac{\sum_{w} \mathrm{SMDI}_{w} \times w^{(m)}_{w}}{\sum_{w} w^{(m)}_{w}},
\] where (\(w^{(m)}_{w}\)) is the proportion of the month accounted for by week (w).
We define a function, get_month_week_cal(), to get a monthly calendar of overlaps. Note that it relies on the find_wday() function previously defined.
#' Calendar of fixed 7-day "weeks" (1--52) overlapped with a given month#'#' @description#' Builds the 52 fixed 7-day blocks for a given year#' (block 1 starts on Jan 1, block k starts on Jan 1 + 7*(k-1) days),#' computes each block's overlap (in days) with the specified month,#' and returns per-block weights equal to overlap / days-in-month.' #' #' @param year Year (numeric).#' @param month Month (numeric).#' #' @returns#' A tibble with one row per overlapping block and columns:#' - `year`: the requested year,#' - `month`: the requested month,#' - `week`: fixed 7-day block index in 1...52,#' - `weight_ndays`: overlap days over days in the month.#' get_month_week_cal <-function(year, month) { m_start <- lubridate::make_date(year, month, 1) m_end <- (m_start %m+%months(1)) - lubridate::days(1)# days in the month dates <-seq(lubridate::ymd(m_start), lubridate::ymd(m_end), by ="day") weeks <-sapply(dates, find_wday) ndays_weeks <-tapply(weeks, weeks, length) dplyr::tibble(week =as.integer(names(ndays_weeks)),nb_days =as.integer(ndays_weeks),weight_ndays = nb_days /sum(nb_days) ) |> dplyr::mutate(year = year,month = month,.before =1L )}
We get the calendar of months for monthly aggregations by applying the get_month_week_cal() function to all the (year, month) covering the sample period:
We then proceed to the second step, where we compute the monthly aggregated values for SMDI:
smdi_monthly <- smdi_weekly |>left_join( months_cal, by =c("year", "week"),relationship ="many-to-many" ) |>group_by(cell_id, year, month) |>summarise(# If any missing values in SMDI will lead to NAsSMDI =weighted.mean(SMDI, w = weight_ndays),.groups ="drop" )
Let us have a look at the values for a cell:
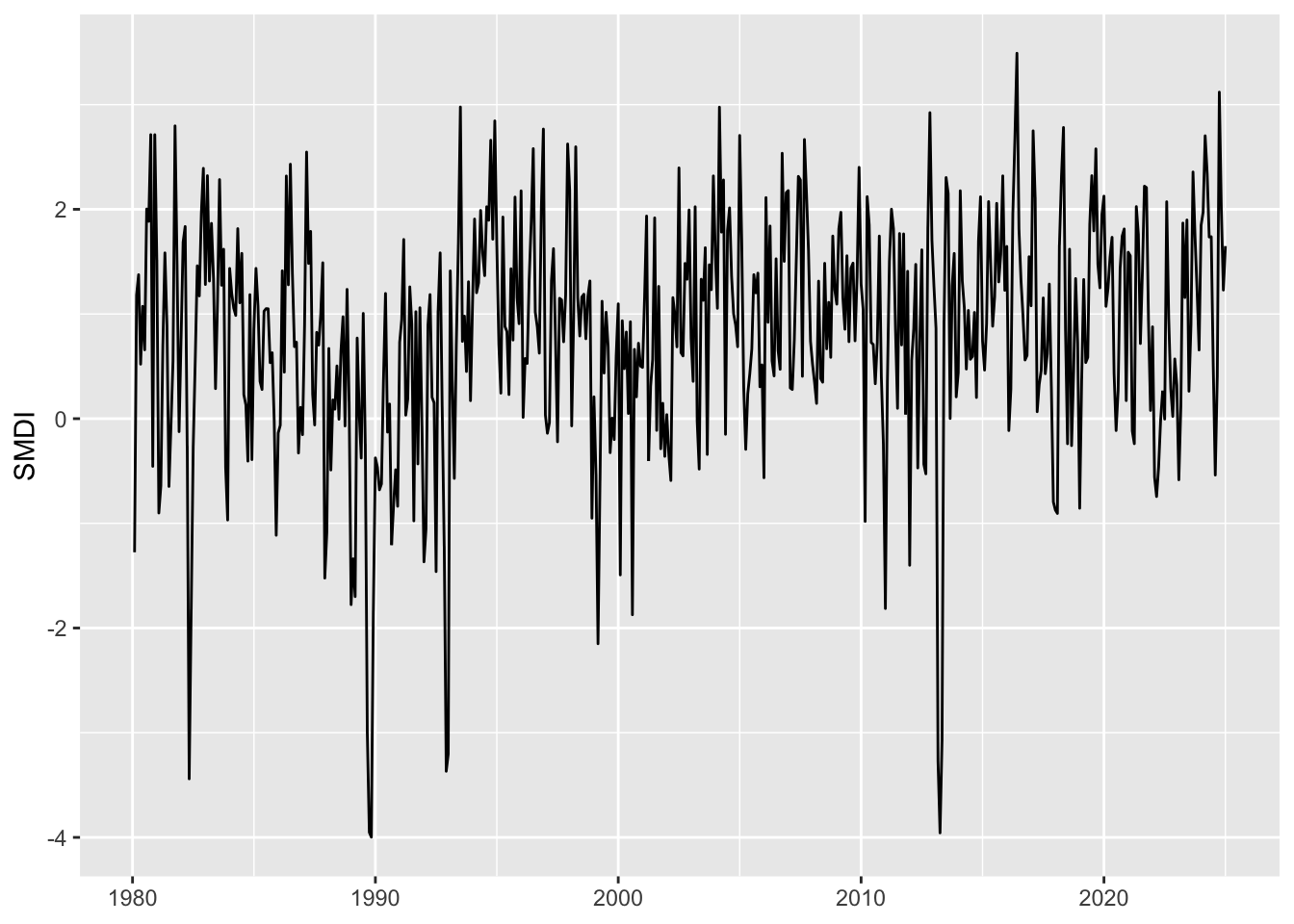
ggplot(data = smdi_monthly |>mutate(date = year + month /12) |>filter(cell_id ==19),mapping =aes(x = date, y = SMDI) ) +geom_line() +labs(x =NULL, y ="SMDI")
Figure 5.2: Monthly SMDI values for a cell in New Zealand. Weekly values range from -4 to +4 indicating very dry to very wet conditions.
5.3.2 Quarterly Aggregation
We may want to aggregate the SMDI values at the quarterly level (Q1–Q4). We follow the same logic as for monthly aggregation, adapting it to quarters:
We first build a quarterly calendar of overlaps. For each year and quarter, we determine how many days of each 7-day week fall within the quarter. This yields a set of weights (\(w^{(q)}_w\)) expressing the fraction of the quarter represented by each week. The weights for a given quarter always sum to 1.
We then compute weighted quarterly SMDI values. Using these weights, we aggregate the weekly SMDI values within each quarter by taking a weighted average, where each week’s contribution is proportional to the number of days it contributes to that quarter: \[
\mathrm{SMDI}_{q} = \frac{\sum_{w} \mathrm{SMDI}_{w} \times w^{(q)}_{w}}{\sum_{w} w^{(q)}_{w}},
\] where (\(w^{(q)}_{w}\)) denotes the proportion of the quarter accounted for by week (w).
The get_quarter_week_cal() function creates the quarterly calendar of overlaps. Again, note that it relies on the find_wday() function previously defined.
#' Calendar weights for fixed 7-day "weeks" (1–52) within a given quarter#'#' @description#' For a given `year` and `quarter`, this function computes the number of days#' from each fixed 7-day block (weeks 1–52, defined from January 1 in 7-day#' increments) that fall within that quarter, along with their normalized#' weights. Any remaining days beyond day 364 (e.g., Dec 31 in common years,#' or Dec 30–31 in leap years) are assigned to week 52.#' #' @param year Year (numeric).#' @param quarter Quarter (numeric).#' #' @returns#' A tibble with one row per overlapping block and columns:#' - `year`: the requested year,#' - `quarter`: the requested quarter,#' - `week`: fixed 7-day block index in 1...52,#' - `weight_ndays`: overlap days over days in the quarter.#' get_quarter_week_cal <-function(year, quarter) { q_start <- lubridate::make_date(year, (quarter -1) *3+1, 1) q_end <- (q_start %m+%months(3)) - lubridate::days(1) dates <-seq(q_start, q_end, by ="day") weeks <-find_wday(dates) ndays_quarter <-tapply(weeks, weeks, length) dplyr::tibble(week =as.integer(names(ndays_quarter)),nb_days =as.integer(ndays_quarter),weight_ndays = nb_days /sum(nb_days) ) |> dplyr::mutate(year = year,quarter = quarter,.before =1L )}
We then proceed to the second step, where we compute the quarterly aggregated values for SMDI:
smdi_quarterly <- smdi_weekly |>left_join( quarters_cal, by =c("year", "week"),relationship ="many-to-many" ) |>group_by(cell_id, year, quarter) |>summarise(# If any missing values in SMDI will lead to NAsSMDI =weighted.mean(SMDI, w = weight_ndays),.groups ="drop" )
Let us have a look at the values for a cell:
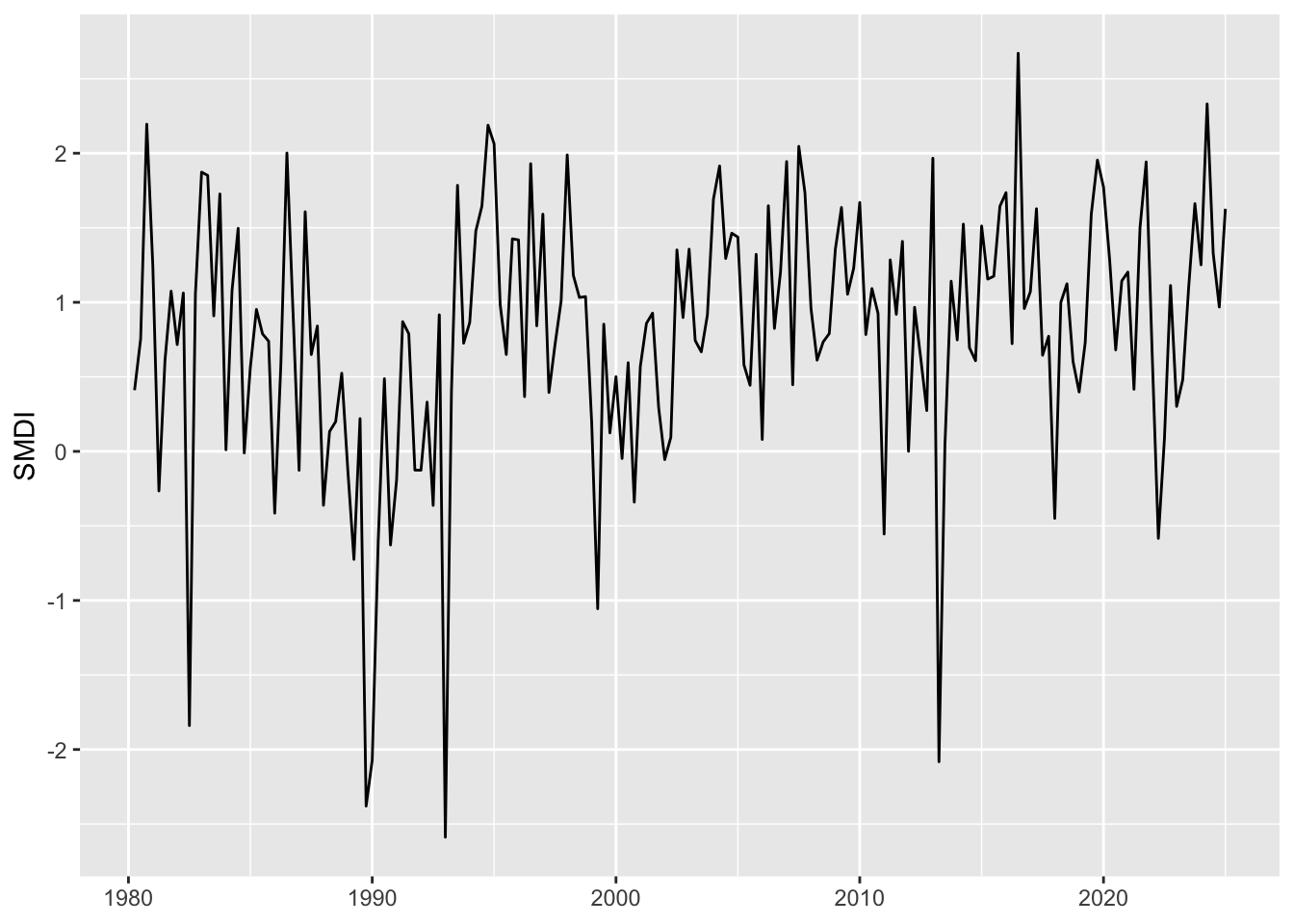
ggplot(data = smdi_quarterly |>mutate(date = year + quarter /4) |>filter(cell_id ==19),mapping =aes(x = date, y = SMDI) ) +geom_line() +labs(x =NULL, y ="SMDI")
Figure 5.3: Quarterly SMDI values for a cell in New Zealand. Quarterly values range from -4 to +4 indicating very dry to very wet conditions.
5.4 Standardized Precipitation-Evapotranspiration Index (SPEI)
We will compute the Standardized Precipitation-Evapotranspiration Index (SPEI), a versatile drought index that uses climatic data to assess the onset, duration, and severity of drought conditions compared to normal conditions Vicente-Serrano, Beguería, and López-Moreno (2010). The SPEI index relies on the precipitation levels and potential evapotranspiration (estimated in Section 5.1).
The SPEI requires:
Monthly precipitation \(P_m\) and monthly potential evapotranspiration \(\text{PET}_m\) as inputs,
Water balance: \(D_m = P_m - \text{PET}_m\),
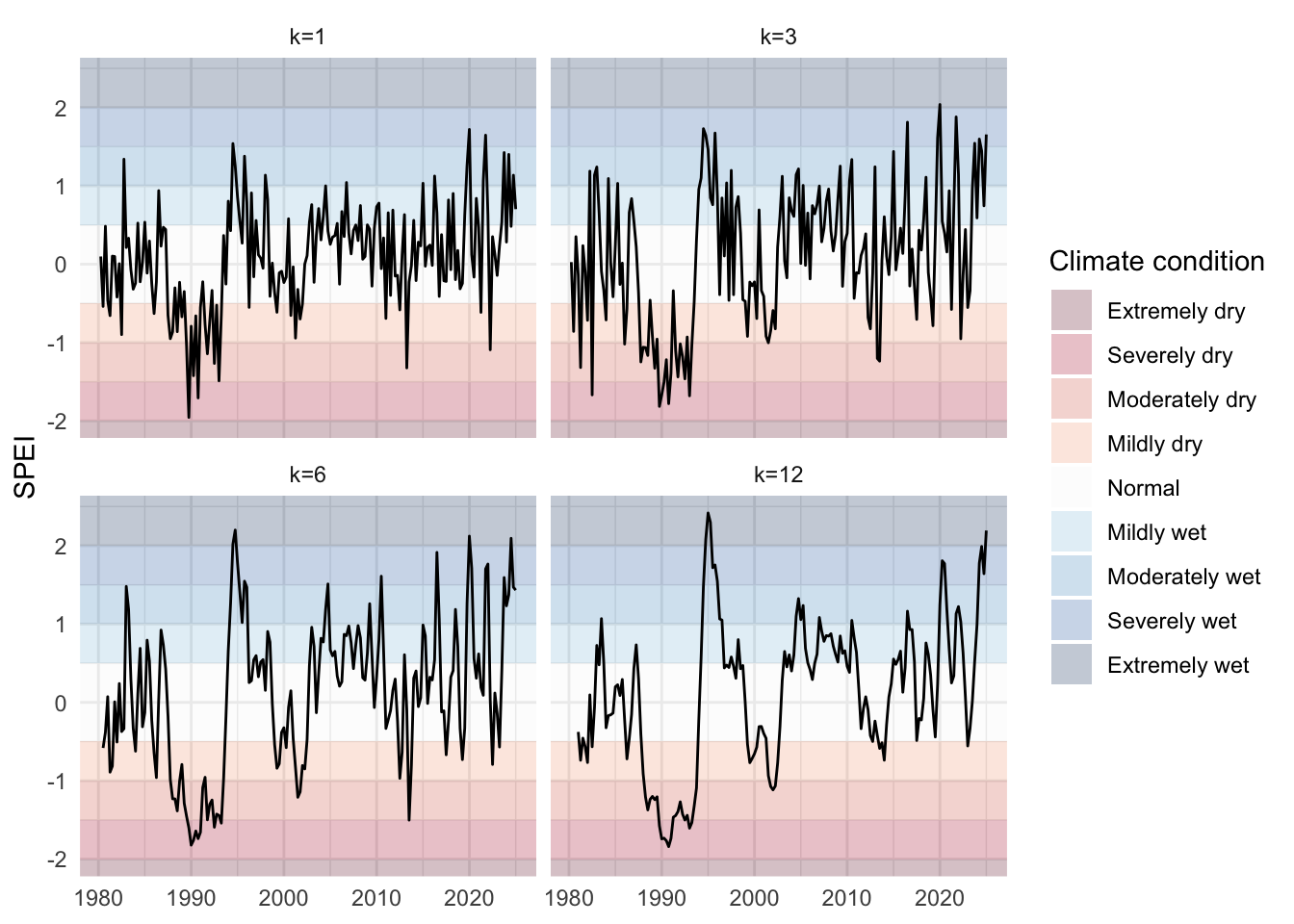
A scale \(k\), usually in \(\{1,2,3,6,12,24\}\), which defines the width (in months) for rolling accumulations. This scale thus controls for the magnitude of the memory,
A calibration window (we will use 1981–2010).
Table 5.1: SPEI values and corresponding climate conditions.
SPEI
Climate condition
SPEI \(\geq\) 2.0
Extremely wet
1.5 \(\leq\) SPEI < 2.0
Severely wet
1.0 \(\leq\) SPEI < 1.5
Moderately wet
0.5 < SPEI < 1.0
Mildly wet
−0.5 \(\leq\) SPEI \(\leq\) 0.5
Normal
−1.0 < SPEI < −0.5
Mildly dry
−1.5 < SPEI \(\leq\) −1.0
Moderately dry
−2.0 < SPEI \(\leq\) −1.5
Severely dry
SPEI \(\leq\) −2.0
Extremely dry
First, we need to compute monthly aggregation of required weather variables, at the grid cell level.
#' Compute Standardized Precipitation-Evapotranspiration Index (SPEI)#' #' @description#' Computes the Standardized Precipitation–Evapotranspiration Index (SPEI)#' at multiple temporal scales from a monthly climatic water balance time series.#'#' @param df A data frame containing at least the following columns:#' - `ym`: a `Date` or `yearmon`-like variable indicating the month,#' - `year`: numeric year of each observation,#' - `balance`: the monthly climatic water balance, typically #' P - PET (precipitation minus potential evapotranspiration), in millimetres (mm).#' @param scales A numeric vector giving the accumulation periods (in months) #' for which the SPEI is computed. Default to `c(1, 3, 6, 12)`.#' @param ref_start Optional numeric vector of length 2 giving the start year #' and month (e.g., `c(1981, 1)`) of the reference calibration period. #' If `NULL`, the full series is used.#' @param ref_end Optional numeric vector of length 2 giving the end year #' and month (e.g., `c(2010, 12)`) of the reference calibration period. #' If `NULL`, the full series is used.#'#' @details#' For each accumulation period `k` in `scales`, the function:#' 1. Builds a monthly time series (`ts`) of the climatic water balance with #' frequency 12. #' 2. Fits the [SPEI::spei()] model for the given scale `k`. #' 3. Extracts the standardized fitted values. #'#' The output includes one column per computed scale, named `SPEI_k`, #' where `k` is the accumulation period (e.g., `SPEI_3` for 3-month SPEI). #'#' @returns#' A tibble with one row per input observation and the following columns:#' - `ym`: corresponding month. #' - `SPEI_k`: standardized SPEI values for each scale `k`. #' compute_spei <-function(df, scales =c(1, 3, 6, 12),ref_start =NULL, ref_end =NULL) {# Build a ts object for water balance with frequency = 12 start_year <-min(df$year, na.rm =TRUE) start_month <-month(min(df$ym, na.rm =TRUE)) bal_ts <-ts(df$balance, start =c(start_year, start_month), frequency =12)# Run SPEI for each scale spei_list <-lapply(scales, function(k) {if (is.null(ref_start) ||is.null(ref_end)) { fit <- SPEI::spei(bal_ts, scale = k, verbose =FALSE) } else { fit <- SPEI::spei( bal_ts, scale = k, ref.start = ref_start, ref.end = ref_end,verbose =FALSE ) }# Extract the fitted standardized values as a numeric vector spei_values <-as.numeric(fit$fitted)tibble(!!paste("SPEI", k, sep ="_") := spei_values ) })bind_cols(spei_list) |>mutate(ym = df$ym, .before =1L)}
The reference period will be Jan. 1981 to Dec. 200.
# A tibble: 540 × 5
ym SPEI_1 SPEI_3 SPEI_6 SPEI_12
<date> <dbl> <dbl> <dbl> <dbl>
1 1980-01-01 0.457 NA NA NA
2 1980-02-01 -0.0726 NA NA NA
3 1980-03-01 -0.0889 0.0265 NA NA
4 1980-04-01 -1.74 -0.917 NA NA
5 1980-05-01 0.271 -0.820 NA NA
6 1980-06-01 -0.145 -0.836 -0.582 NA
7 1980-07-01 0.351 0.142 -0.567 NA
8 1980-08-01 0.791 0.333 -0.351 NA
9 1980-09-01 0.310 0.579 -0.227 NA
10 1980-10-01 -0.810 0.117 0.0809 NA
# ℹ 530 more rows
Check whether there are infinite values in the resulting values. If that is the case, consider a wider reference period.
The compute_spei() function is then applied to each cell.
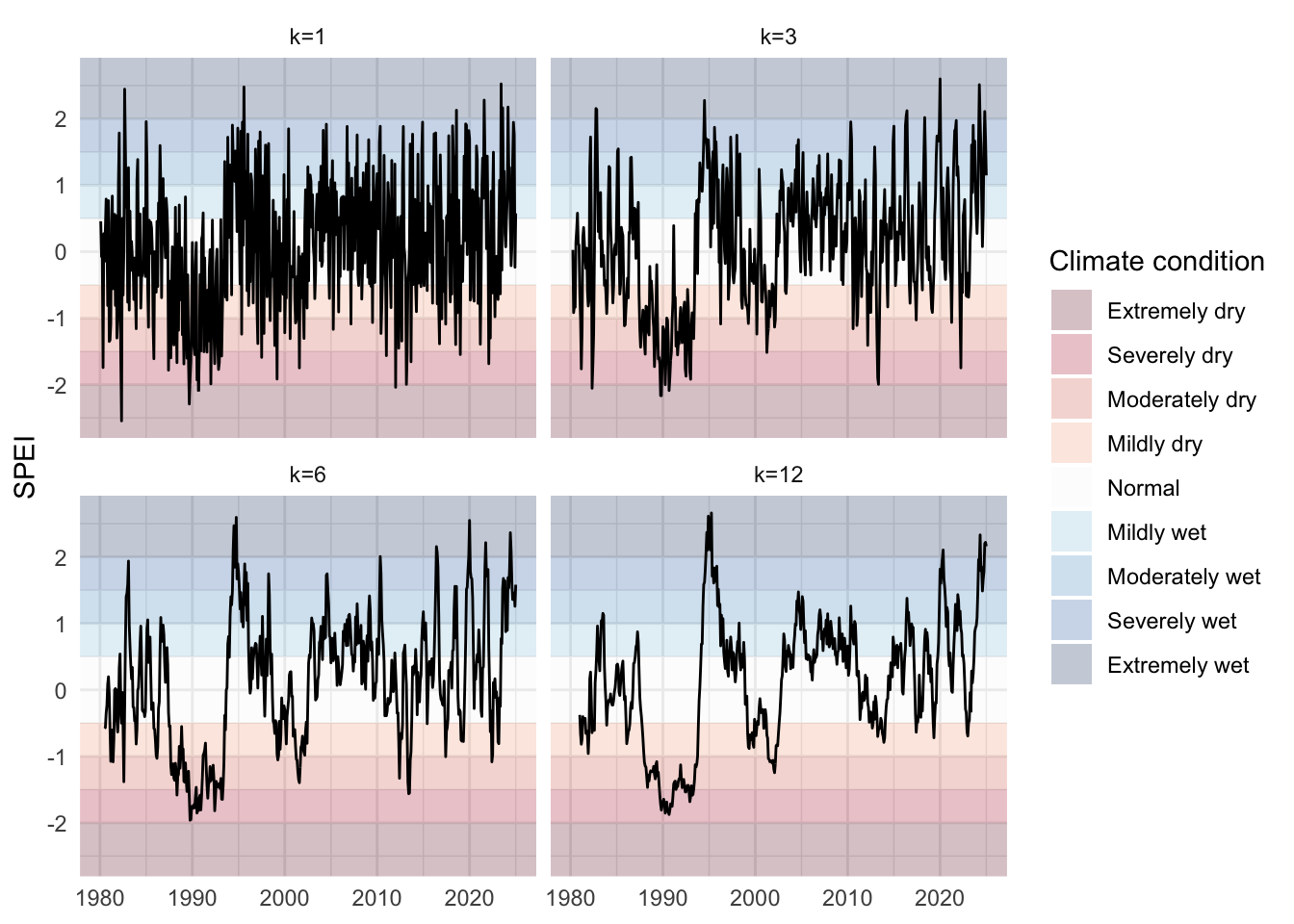
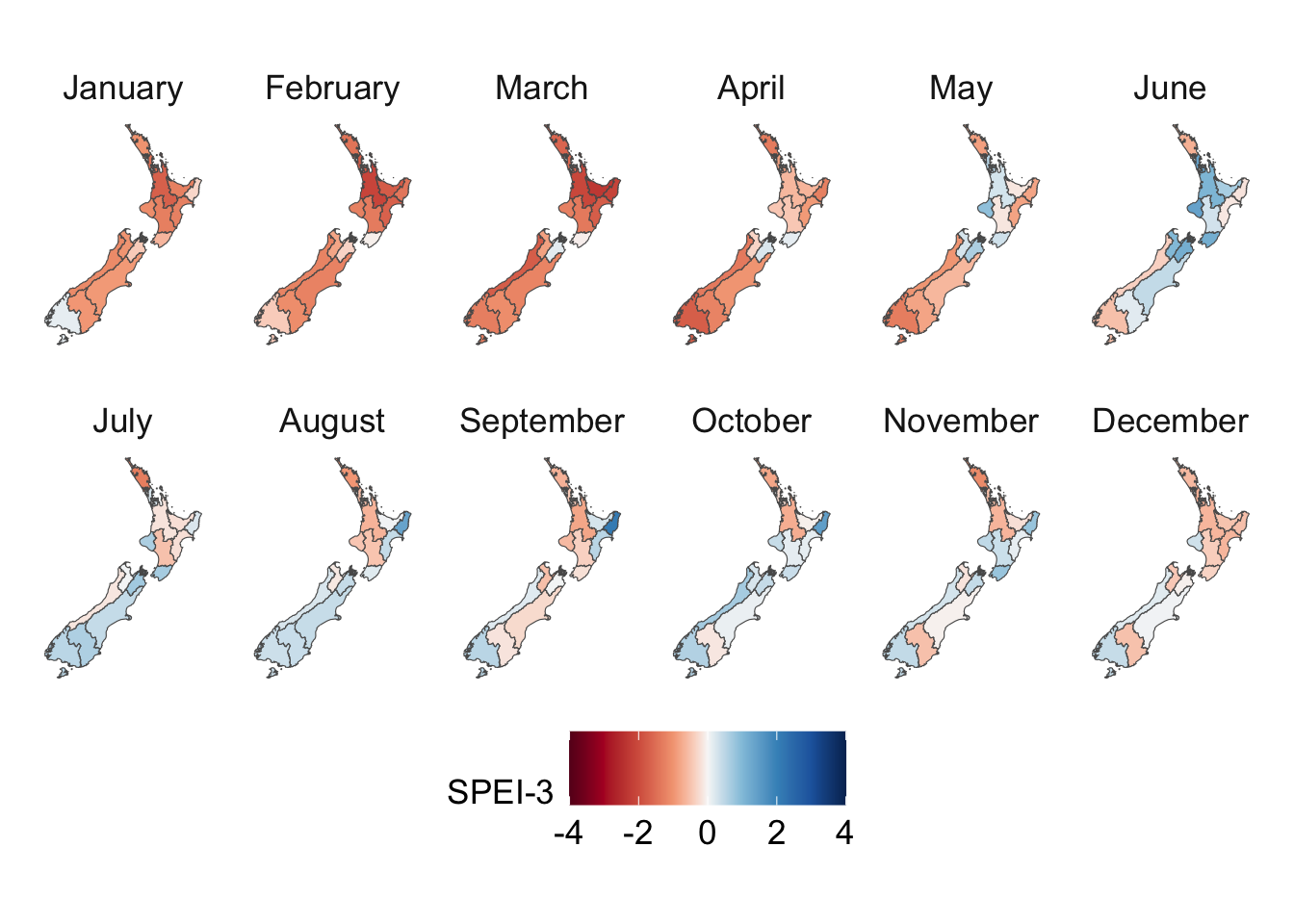
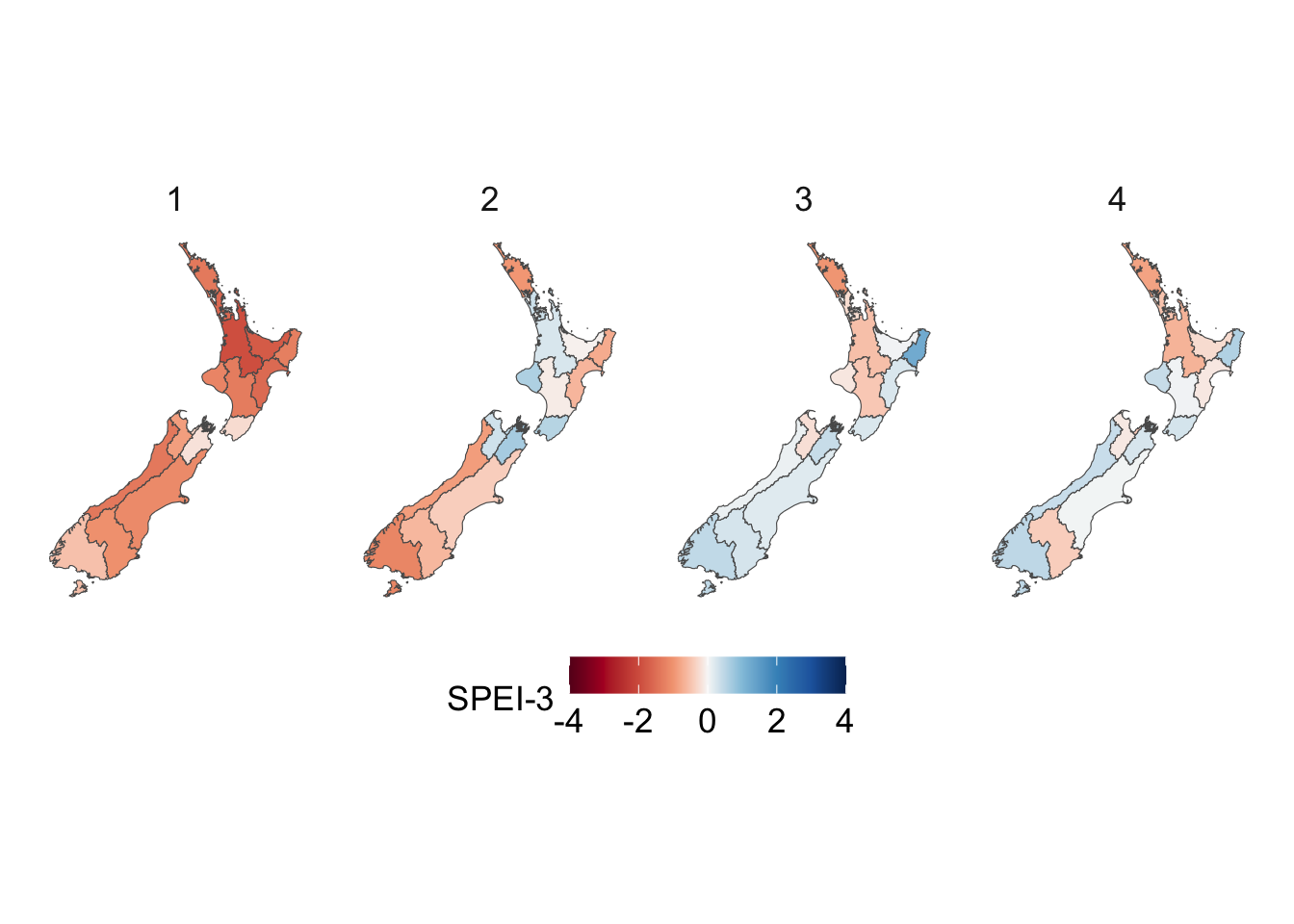
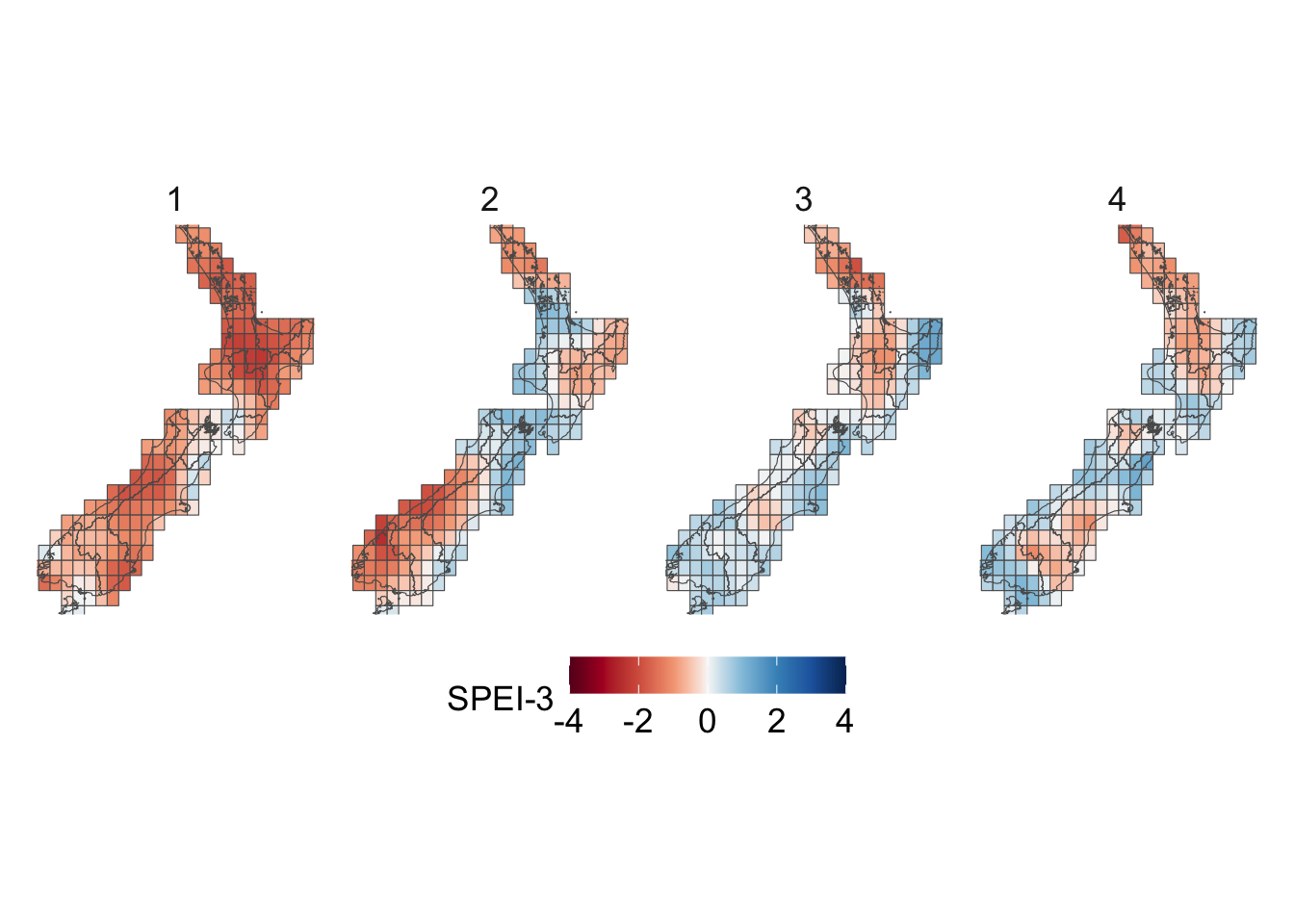
Figure 5.5: Quarterly mean of SPEI for a cell in New Zealand, depending on the accumulation periods (\(k\)). Shaded zones represent climatic conditions by SPEI range
5.5 Temporal Aggregation
We now need to gather the different datasets together. As for the SMDI, we will consider a monthly and a quarterly aggregation.
5.5.1 Monthly Data
First, we compute the total amount of precipitation, the average minimum, maximum, and mean temperatures, at the cell-level, on a monthly basis.
We now have monthly and quarterly weather observations computed at the grid cell level. Our next step is to aggregate these data spatially to match the level of available macroeconomic indicators, which are typically reported at the regional or national scale.
5.6.1 Regional Level
For the regional aggregation, we compute a weighted average of the cell-level values, using as weights the proportion of each cell’s area lying within the corresponding region.
We need the maps of the country of interest. We use the st_shift_longitude() here because New Zealand’s boundaries have values straddling 180 degrees.
We will compute the weighted mean of the following weather variables (this needs to be updated if more weather metrics are computed):
# The names of the SPEI variablesspei_names <-colnames(country_weather_monthly)[str_detect(colnames(country_weather_monthly), "^SPEI_")]# All the weather variables previously defined:weather_vars <-c("precip", "temp_min", "temp_max", "temp_mean","SMDI", spei_names)
5.6.1.1 Monthly Data
We merge the regional weights with the monthly weather data available at the cell level. During this join, cells intersecting multiple regions appear multiple times in the resulting dataset (once per overlapping region) with their contribution differentiated by the corresponding intersection weight.
region_weather_monthly <- country_weather_monthly |>left_join( inter_tbl |>select(GID_1, region, cell_id, w_cell_region),by =c("cell_id"),relationship ="many-to-many"# a cell can be in multiple regions ) |>group_by(GID_1, region, country_code, year, month, month_name) |>summarise(across(all_of(weather_vars),~weighted.mean(.x, w = w_cell_region) ),.groups ="drop" )
5.6.1.2 Quarterly Data
We perform the same operation with the quarterly data.
region_weather_quarterly <- country_weather_quarterly |>left_join( inter_tbl |>select(GID_1, region, cell_id, w_cell_region),by =c("cell_id"),relationship ="many-to-many"# a cell can be in multiple regions ) |>group_by(GID_1, region, country_code, year, quarter) |>summarise(across(all_of(weather_vars),~weighted.mean(.x, w = w_cell_region) ),.groups ="drop" )
5.6.1.3 Maps for Monthly Data
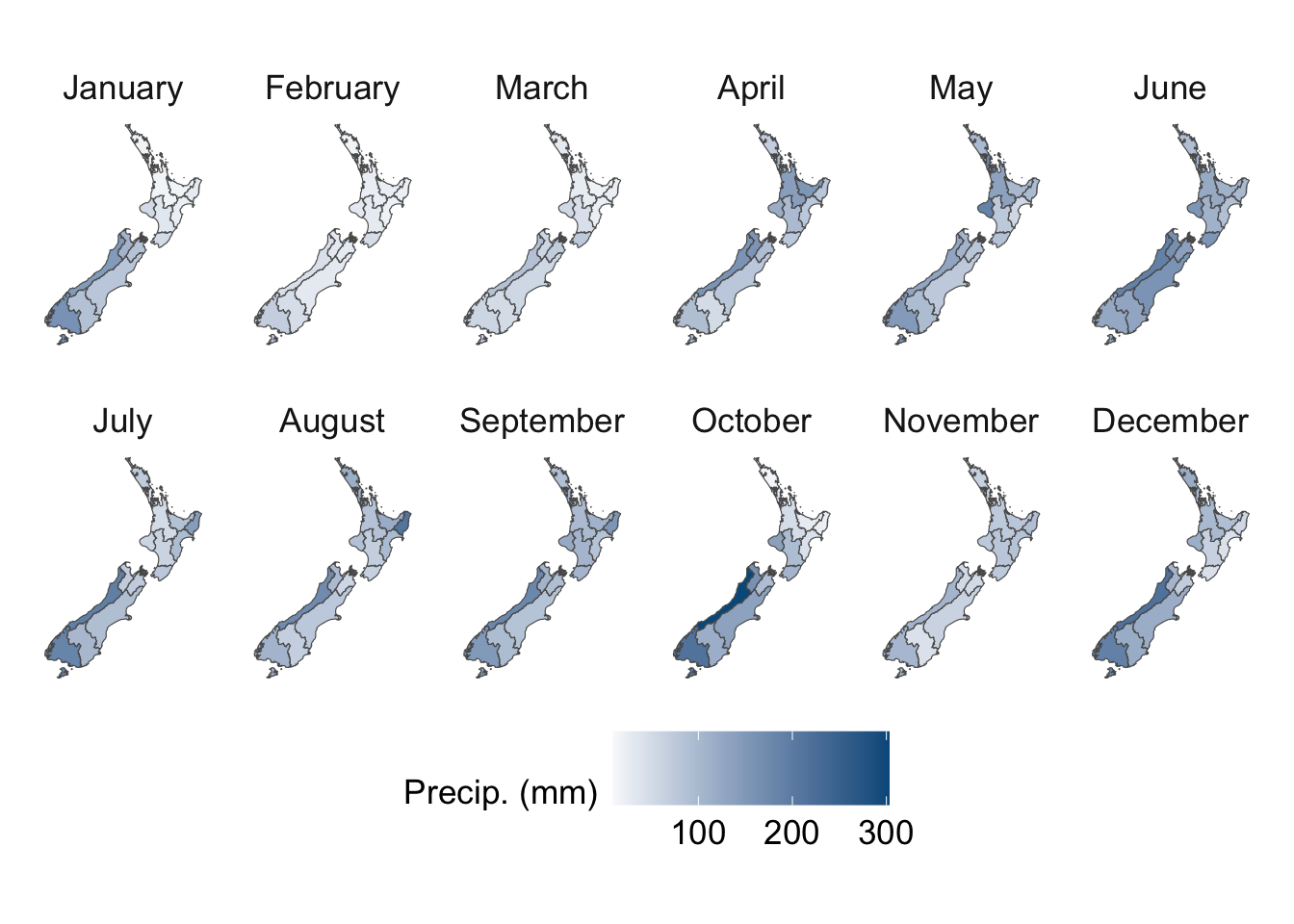
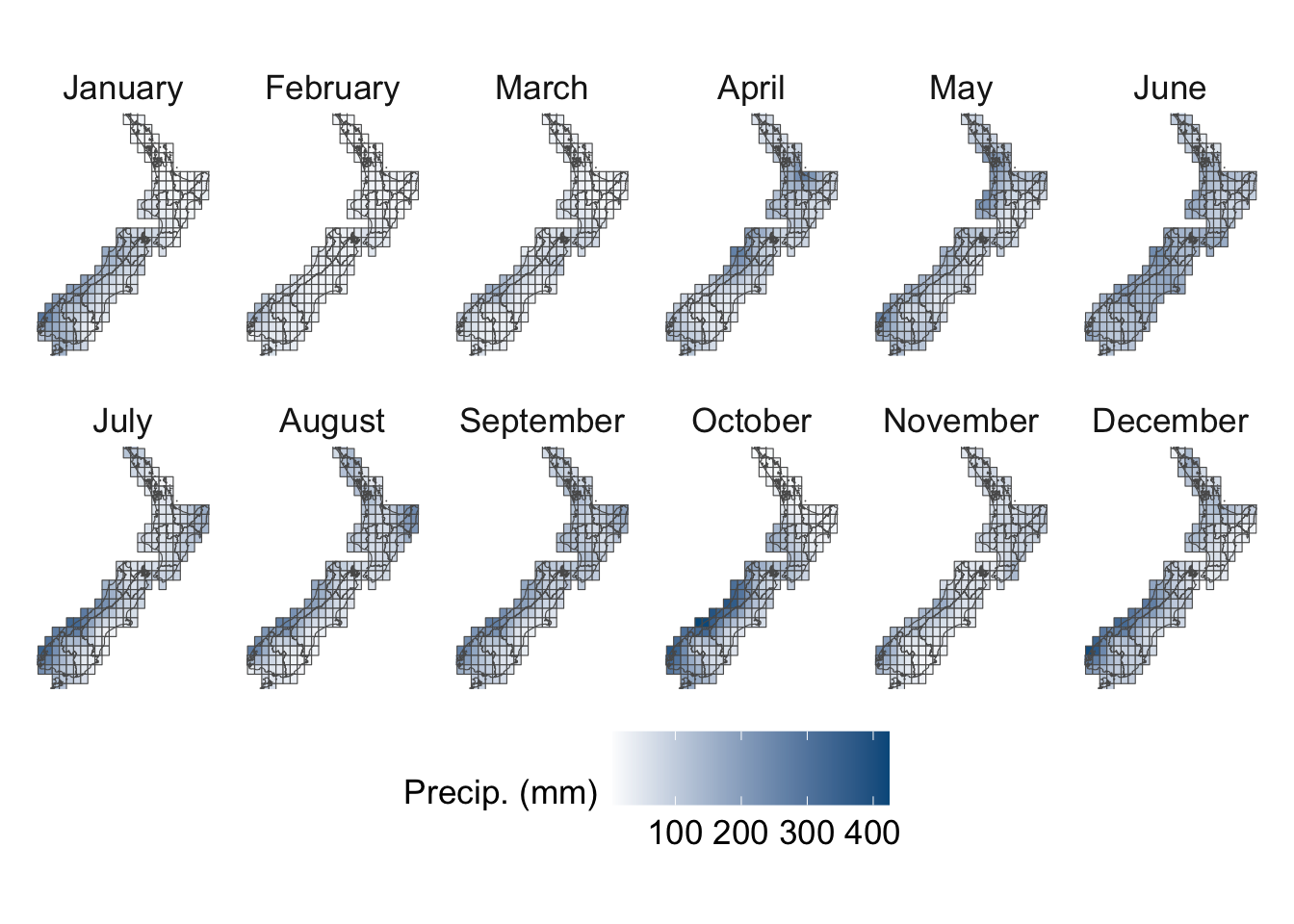
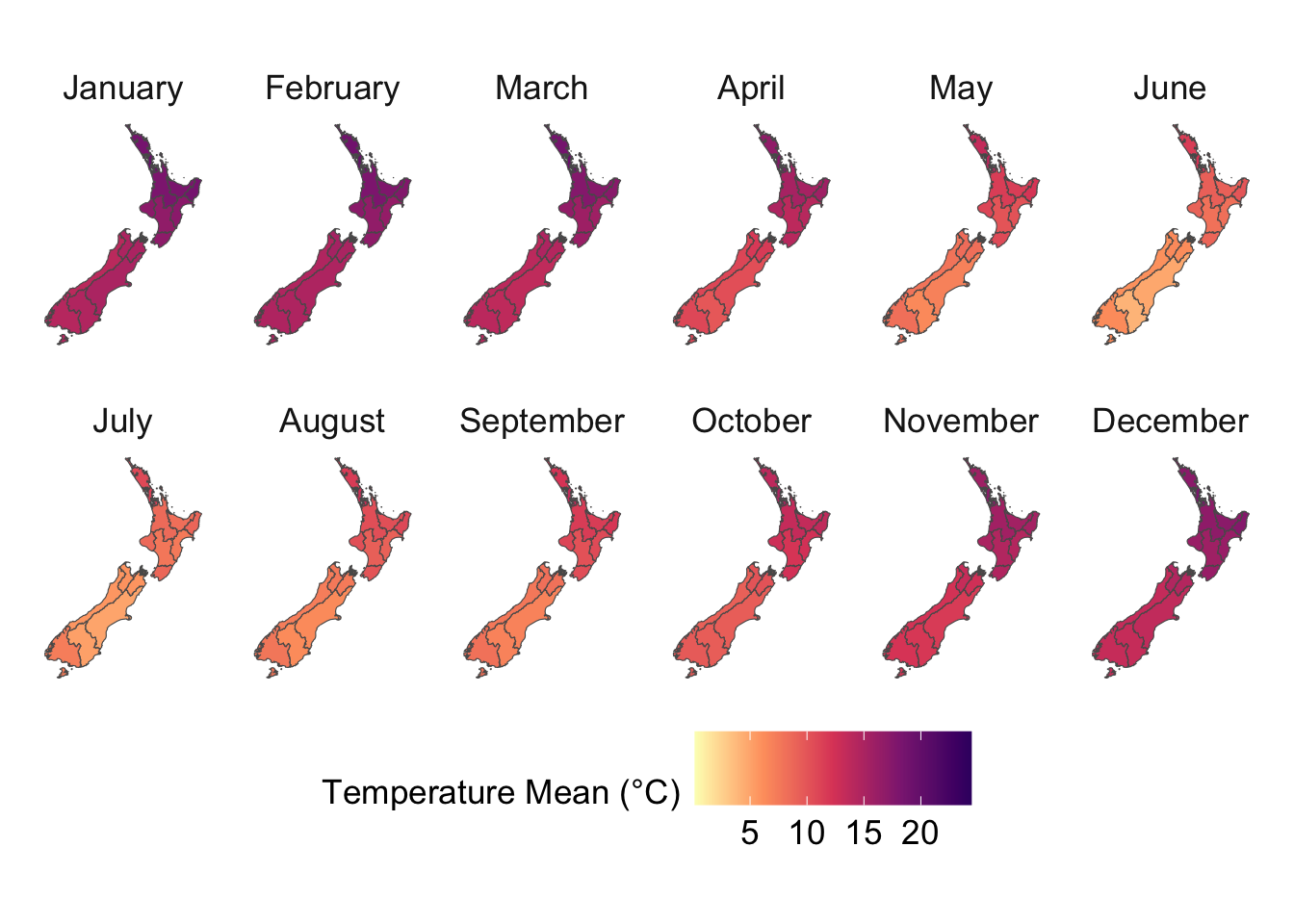
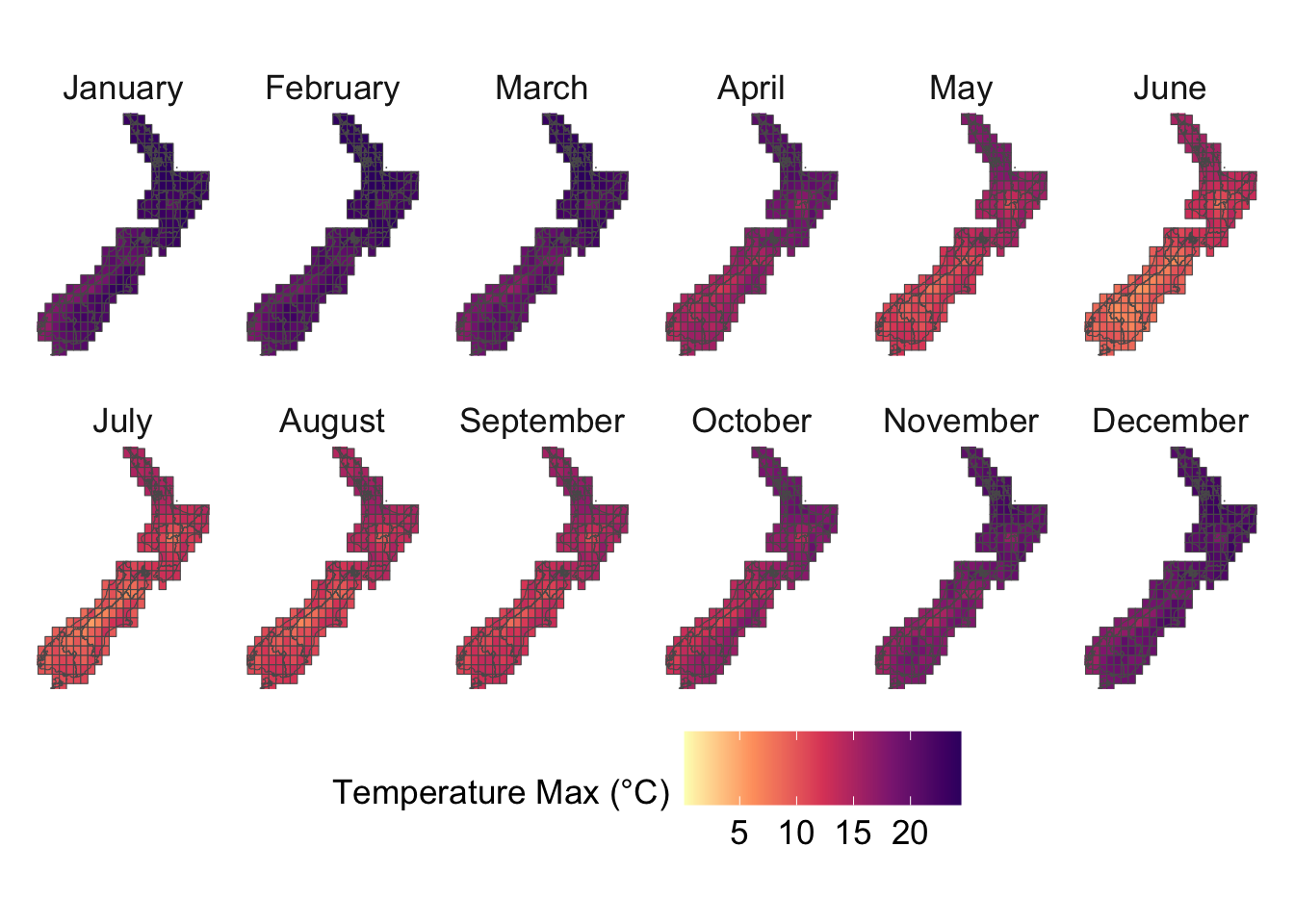
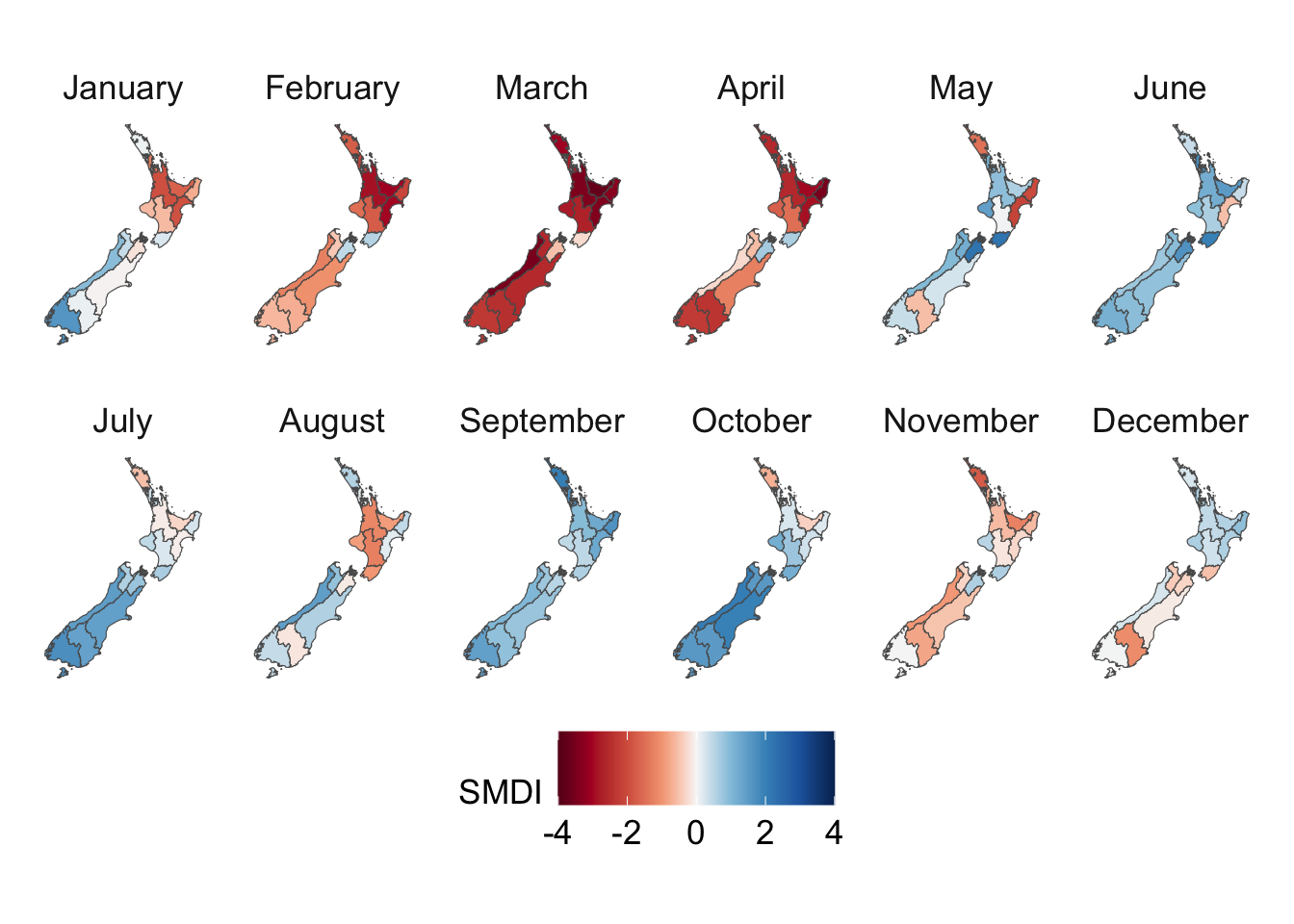
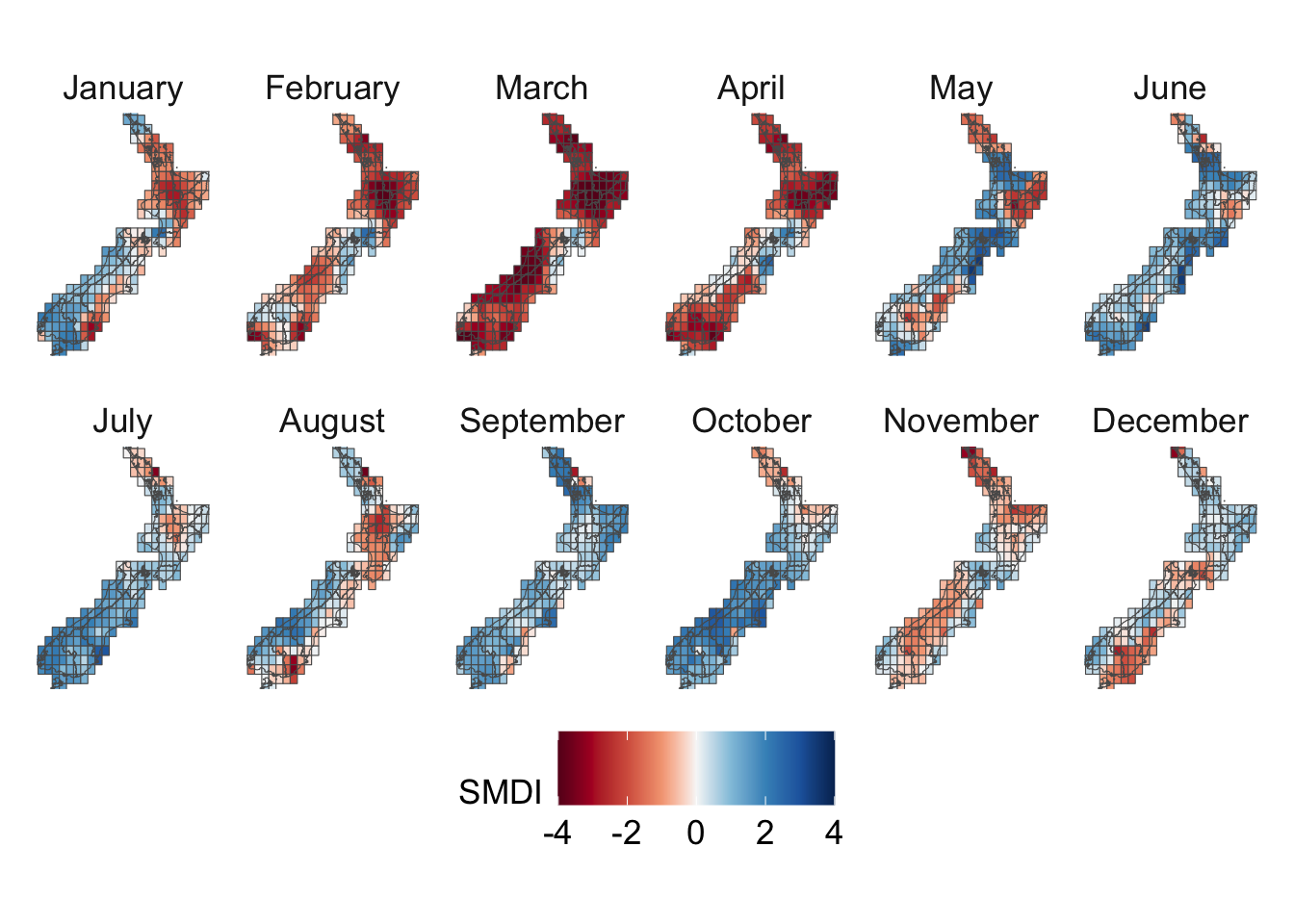
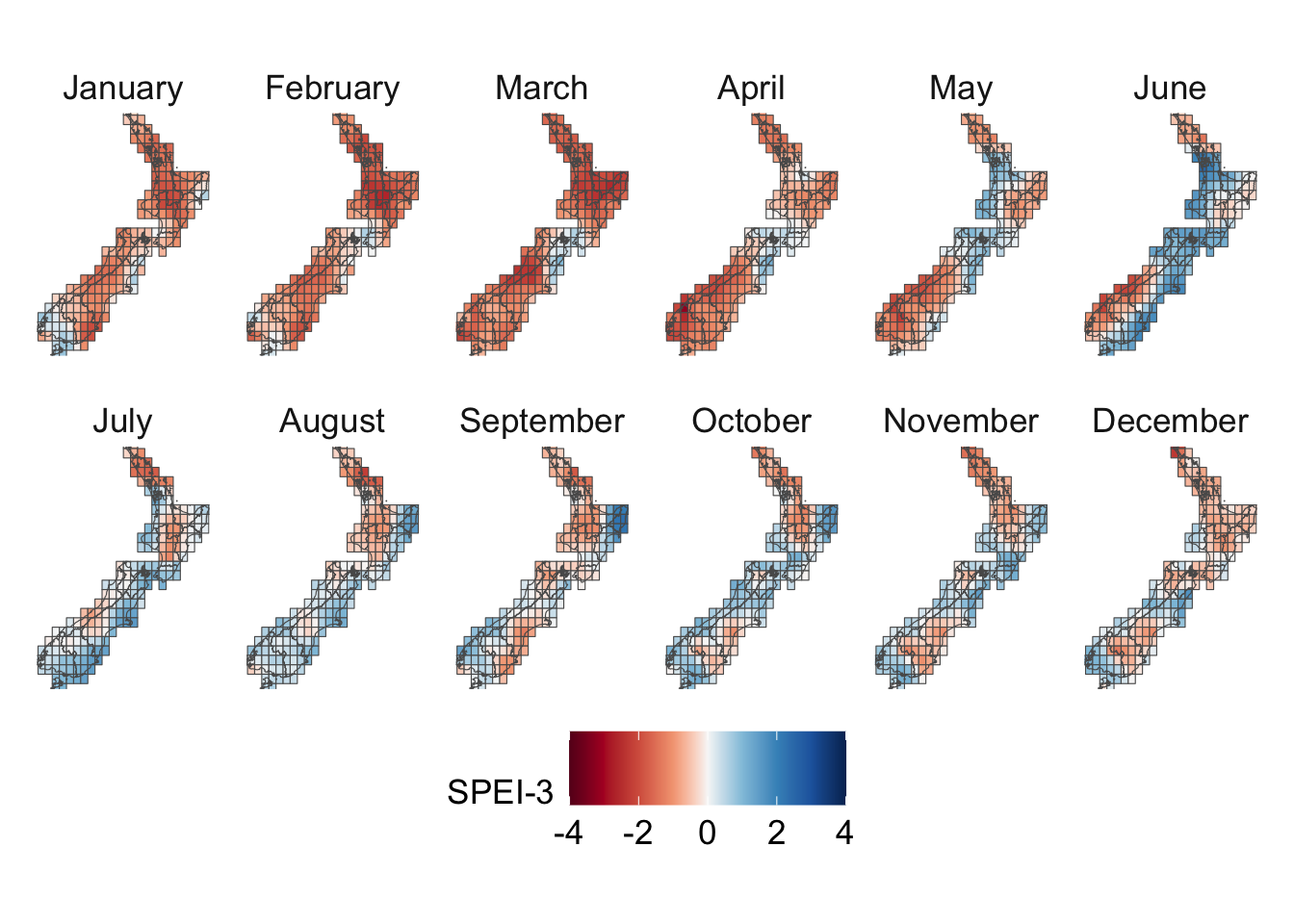
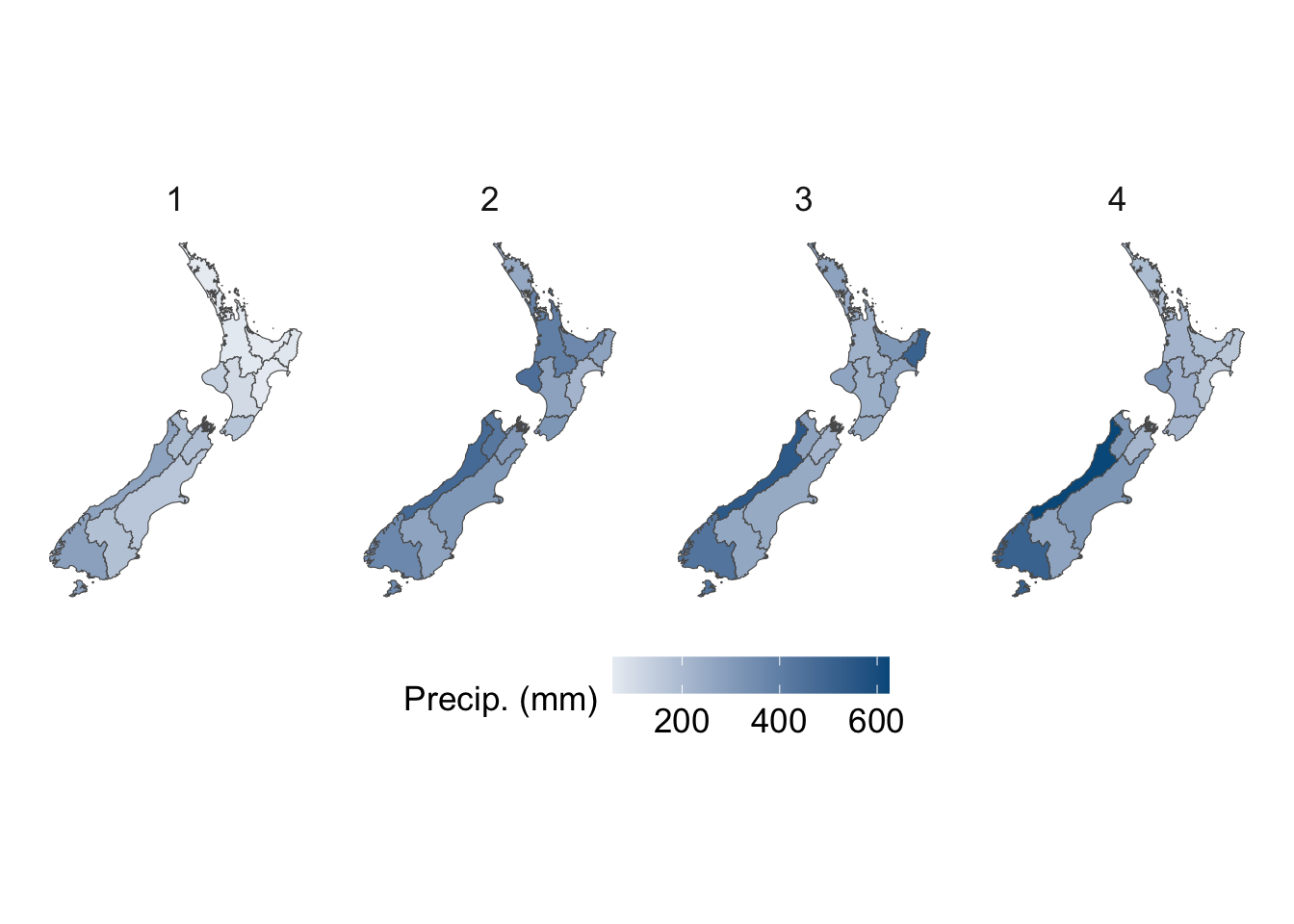
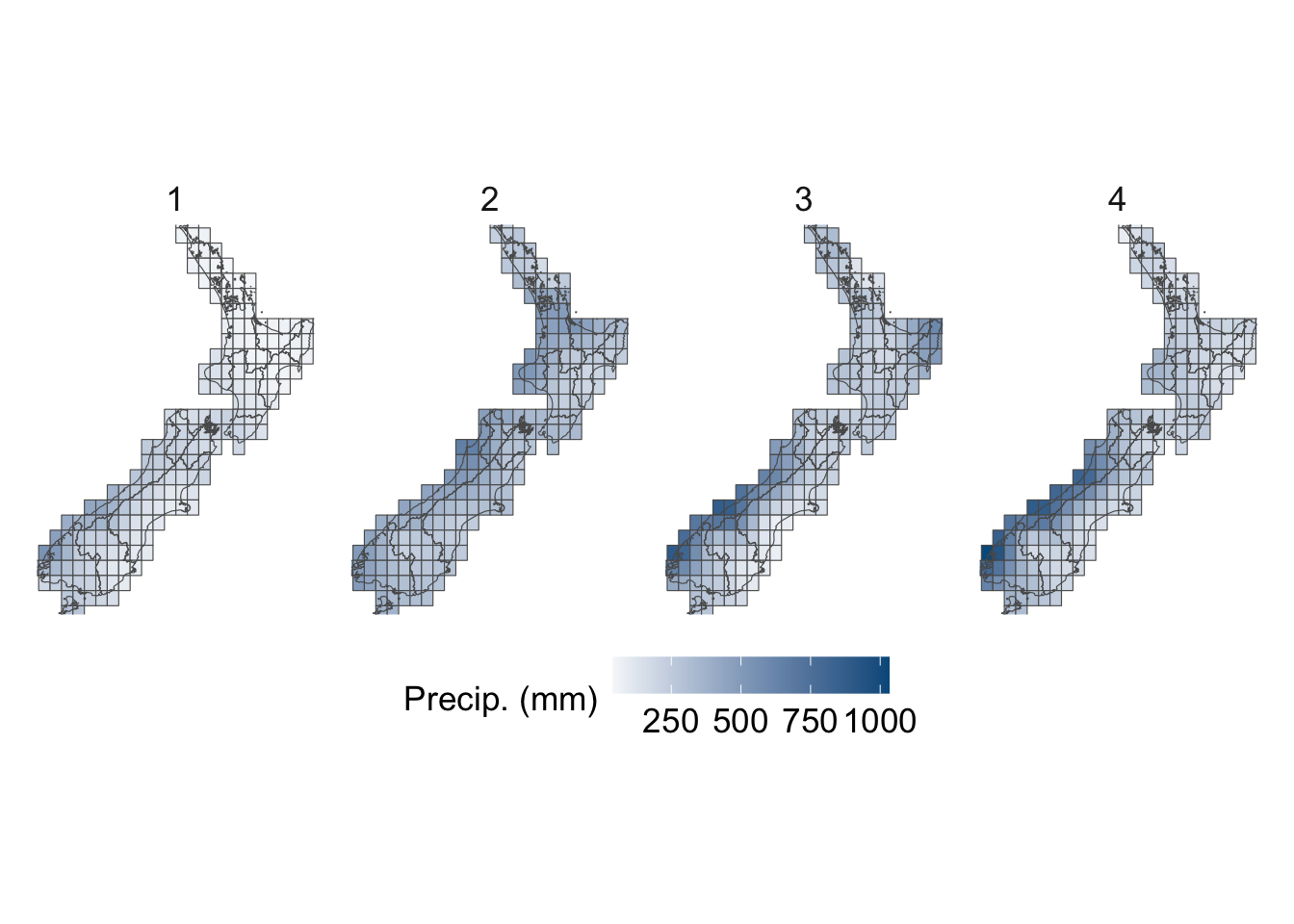
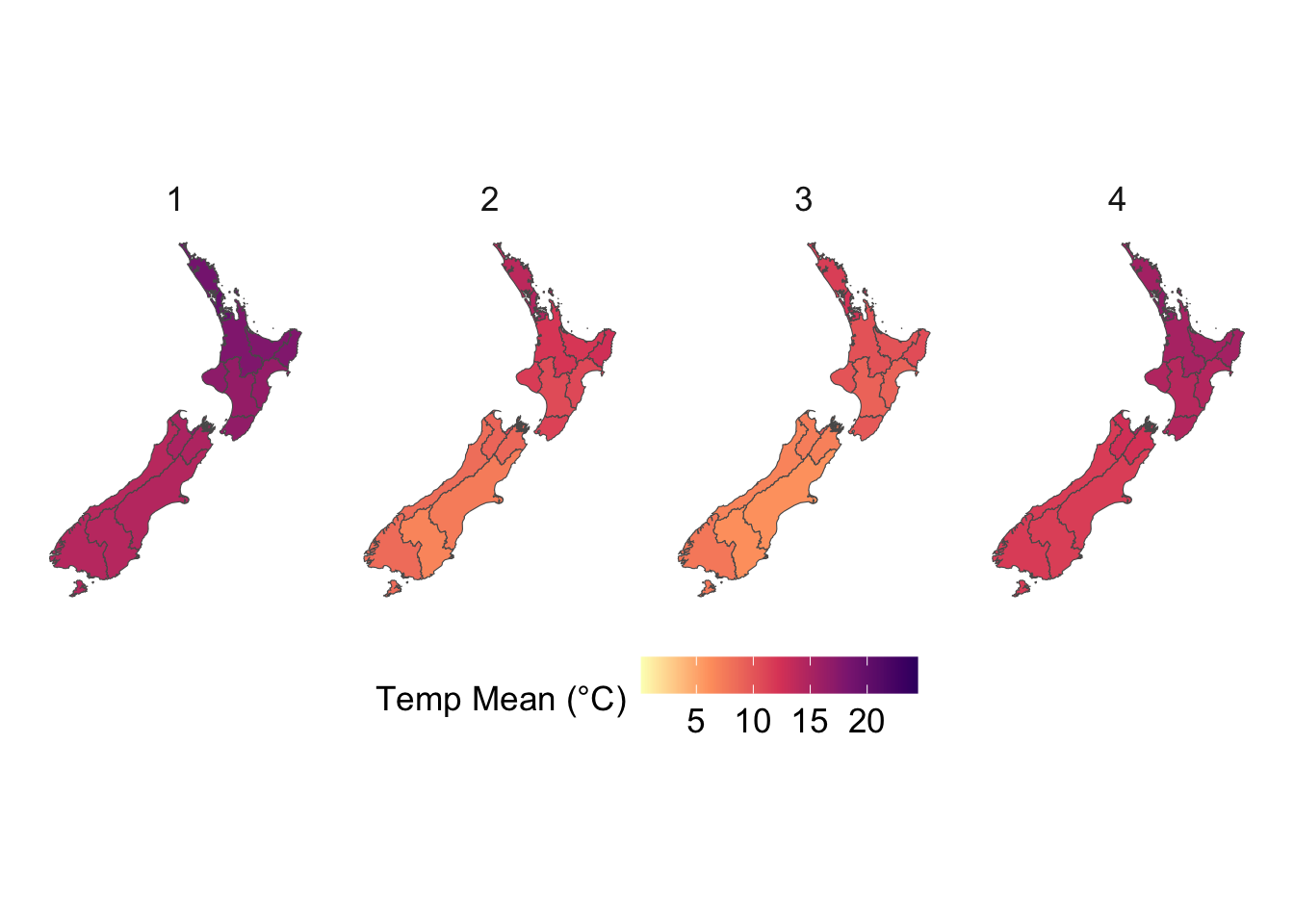
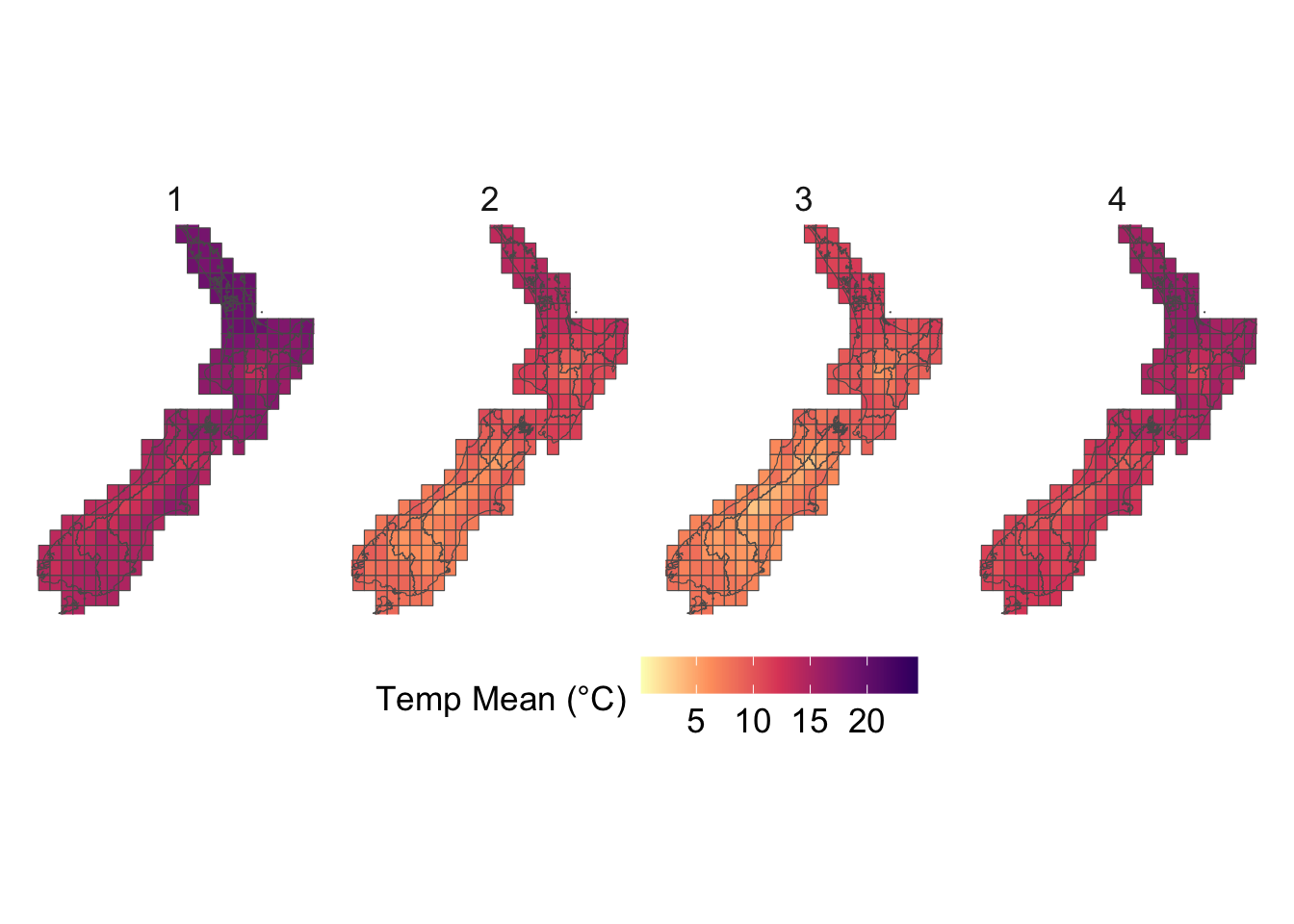
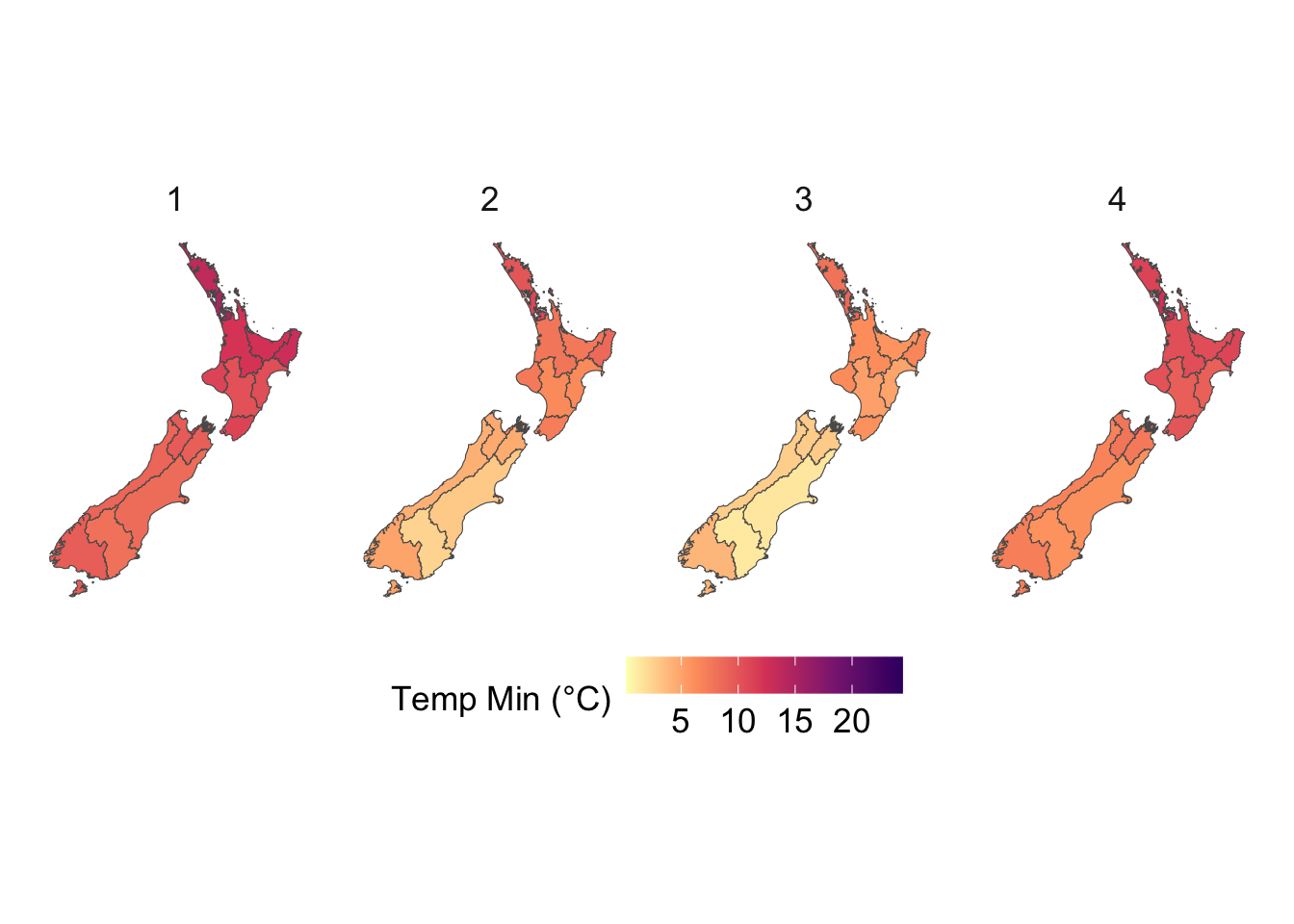
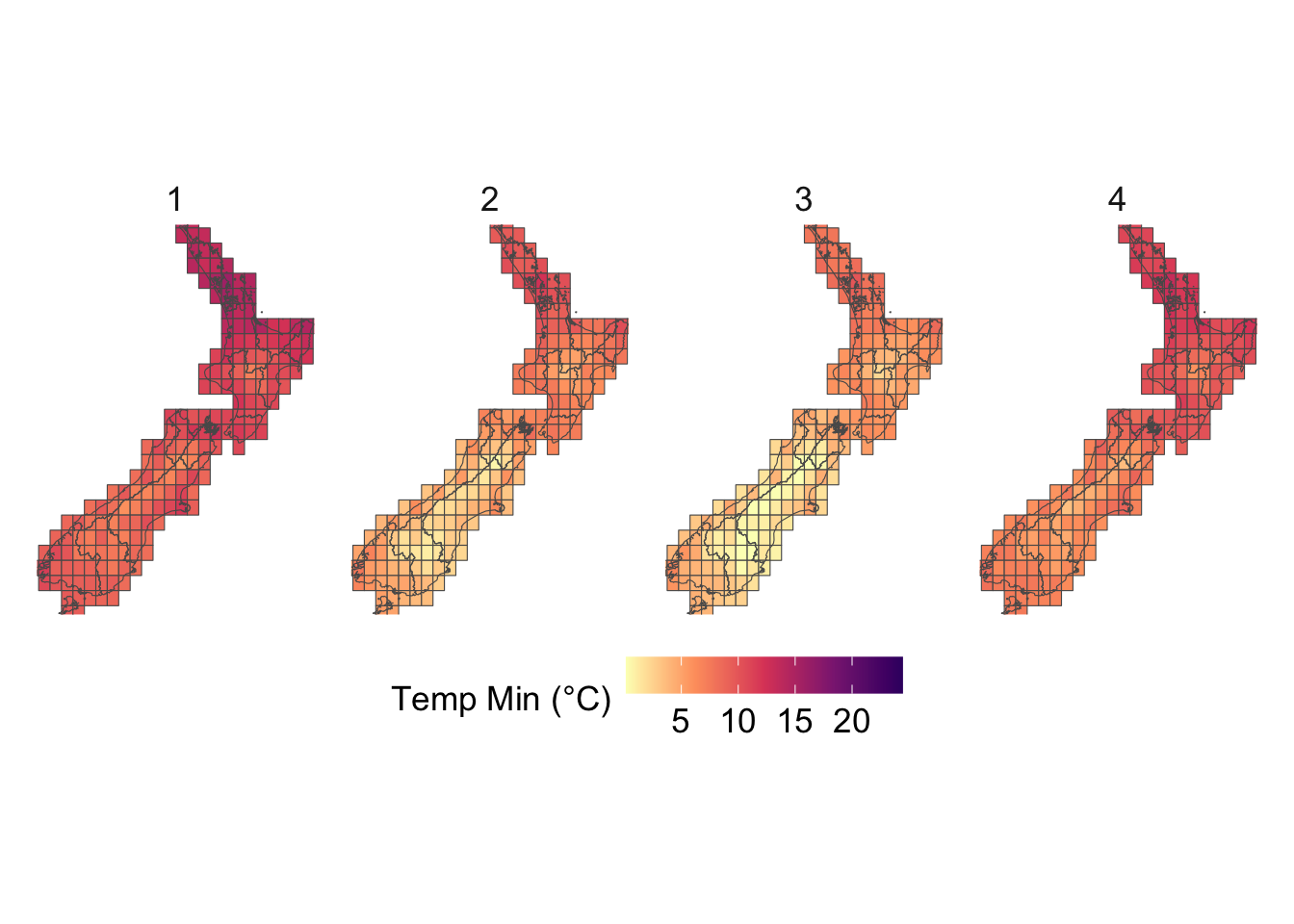
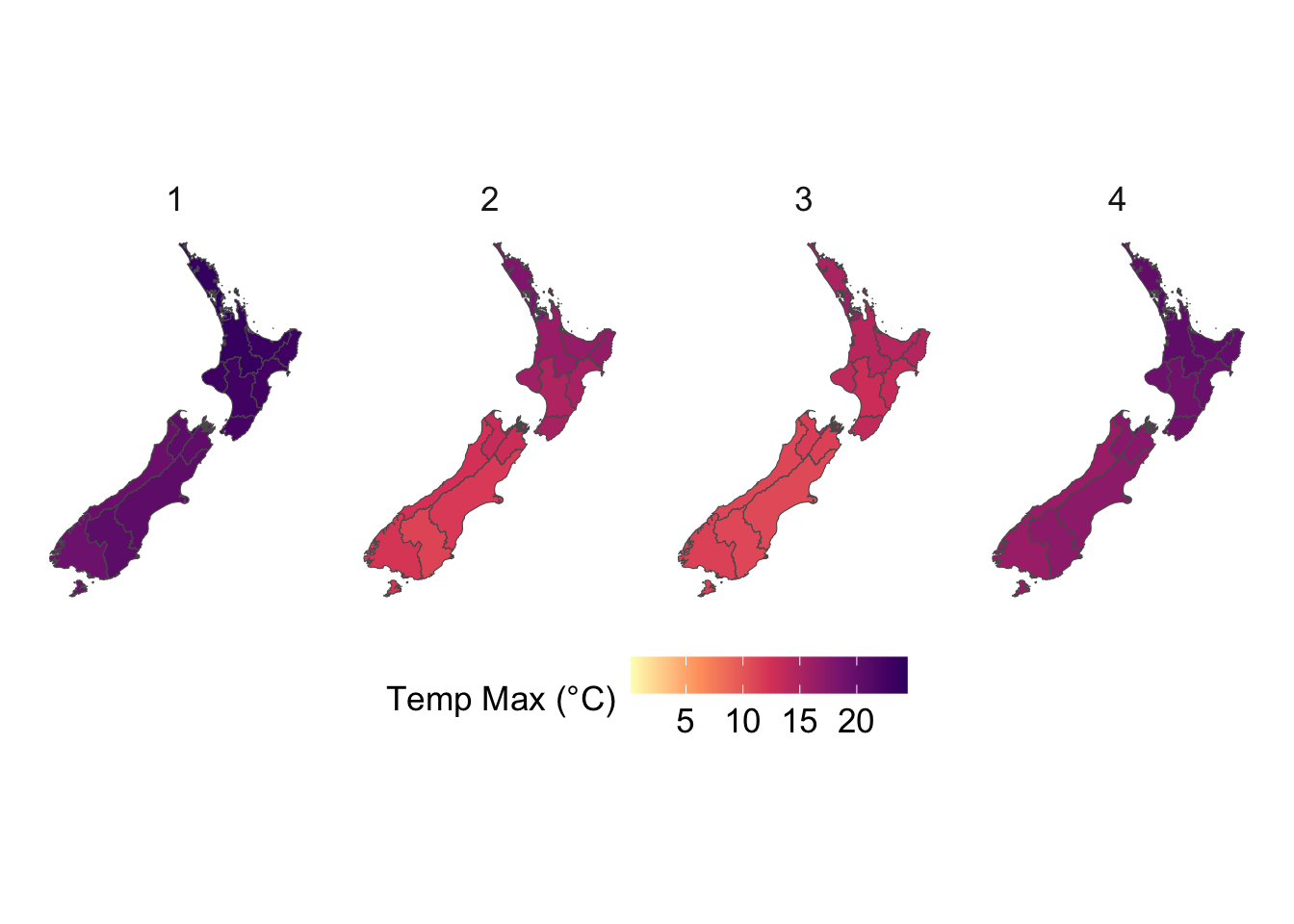
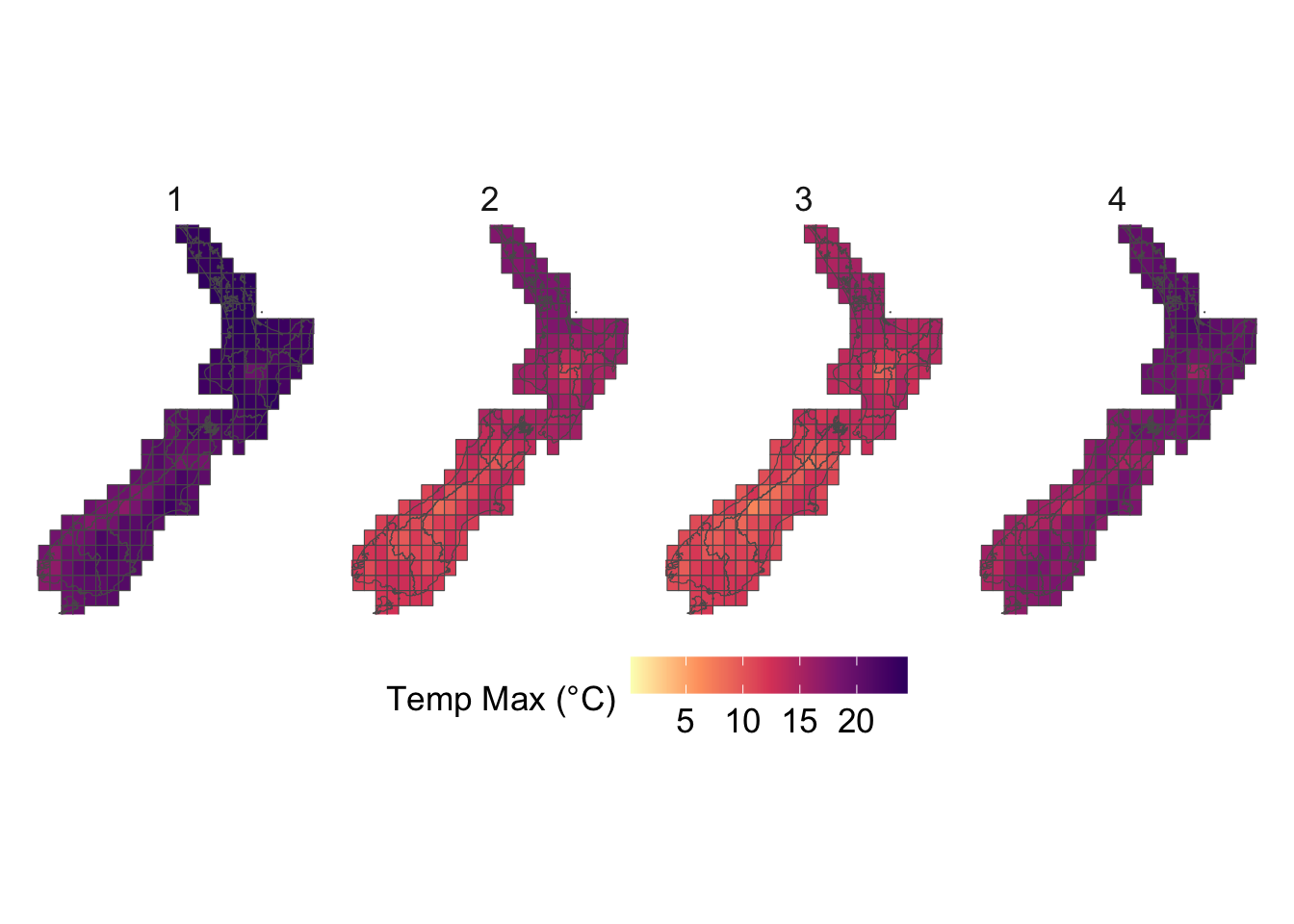
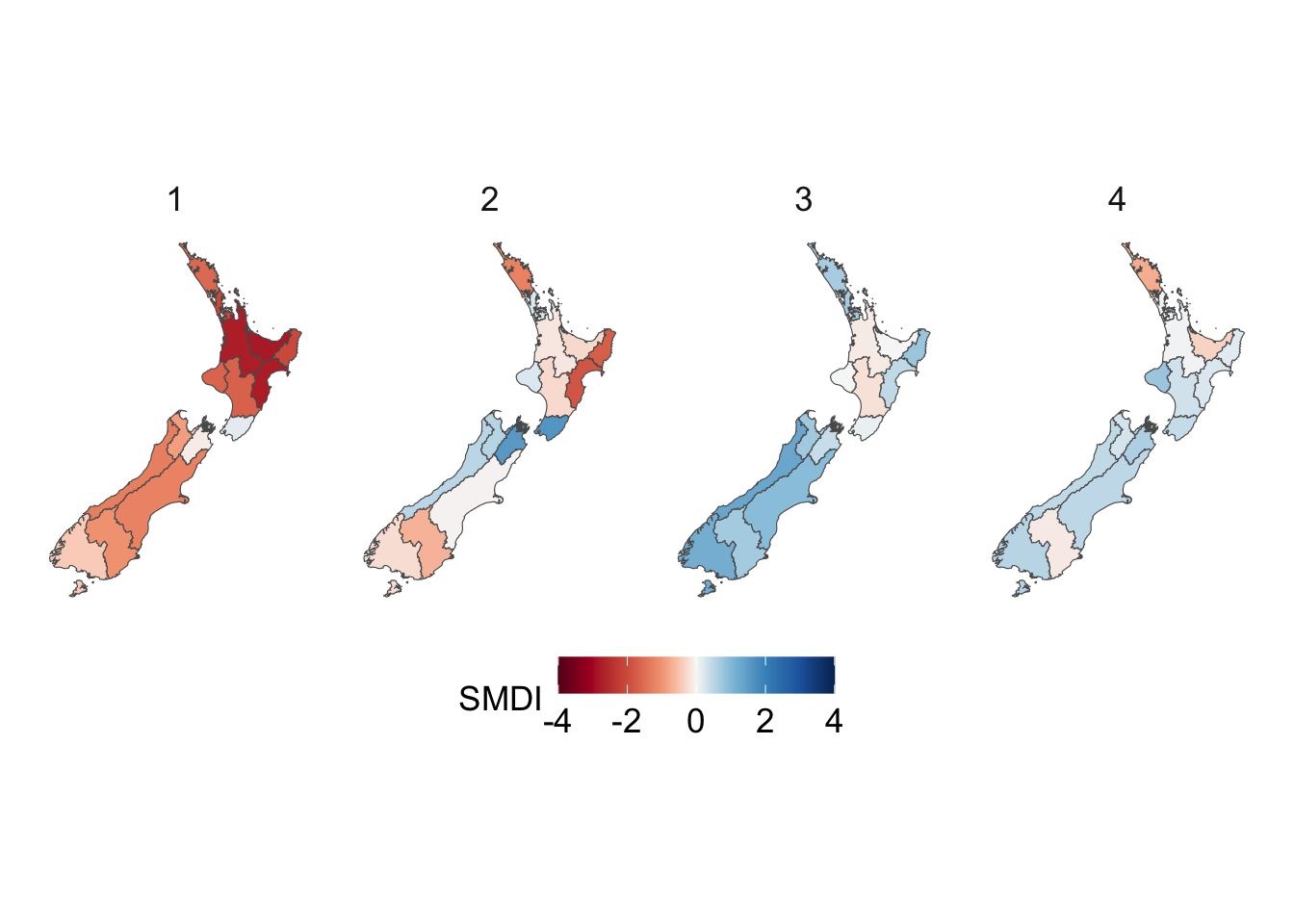
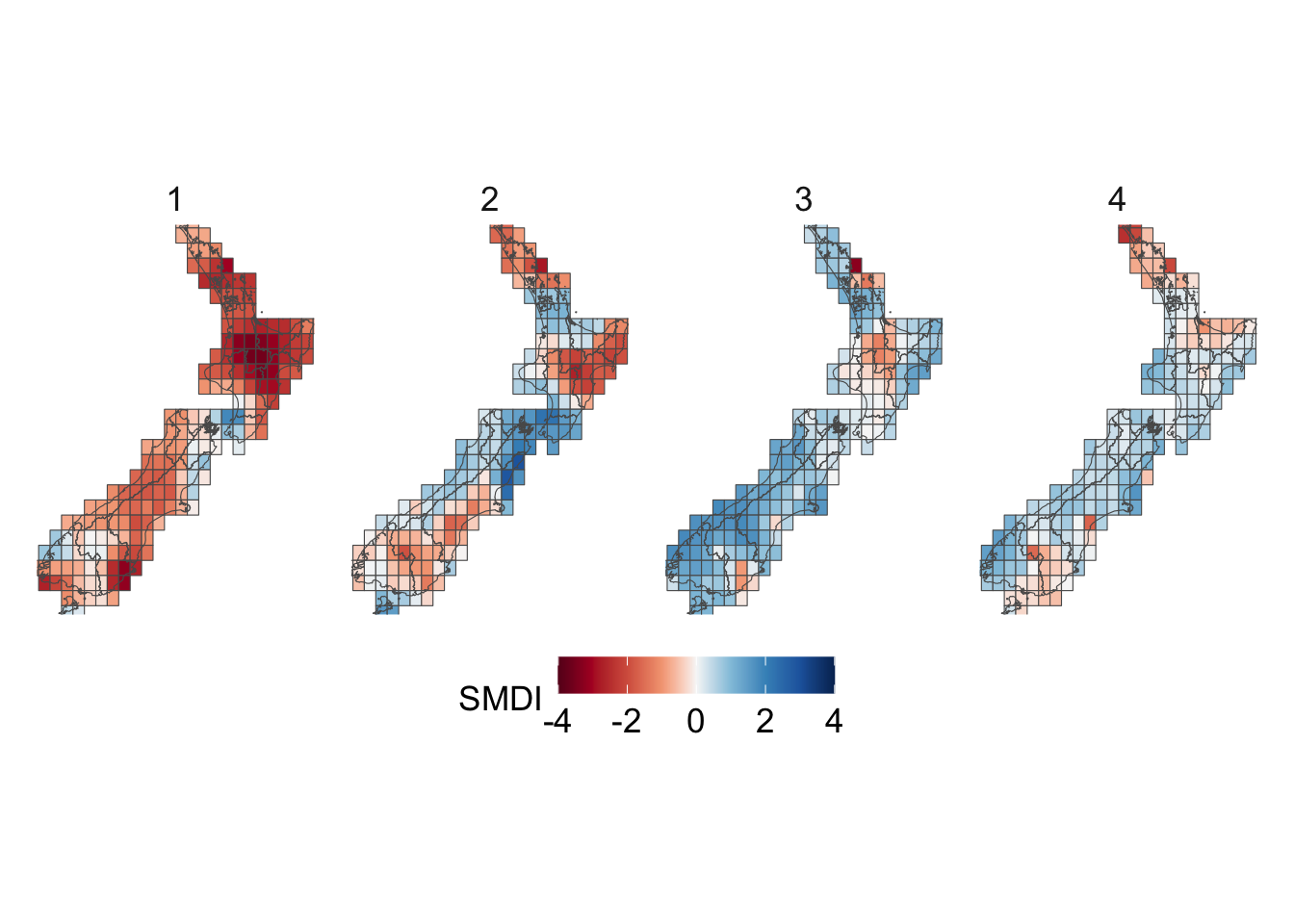
We visualize the aggregated weather by plotting choropleth maps for year 2013. For each month (12 panels), we produce:
Maps at the regional level using area-weighted regional means,
Maps at the cell level using cell means.
To be able to compare the values across months, we construct one map layer per month and then bind them into a single sf object for faceting.
# For region layersdata_map <-vector(mode ="list", length =12)for (i in1:12) { data_map[[i]] <- maps_level_1_NZ |>inner_join( region_weather_monthly |>filter(year ==2013, month ==!!i),by =c("GID_1", "NAME_1"="region") )}data_map <-list_rbind(data_map) |>st_as_sf()# For cell layersdata_map_cells <-vector(mode ="list", length =12)for (i in1:12) { data_map_cells[[i]] <- cells_sf |>inner_join( country_weather_monthly |>filter(year ==2013, month ==!!i),by =c("cell_id", "longitude", "latitude") )}data_map_cells <-list_rbind(data_map_cells) |>st_as_sf()
To ensure visual comparability across maps, we use a common color scale for all temperature variables. The code below computes the global minimum and maximum values across both minimum and maximum temperatures and defines a shared color palette that will be applied to every temperature map.
For the Soil Moisture Deficit Index, we define a diverging palette, with warm colors indicating dry conditions and cool colors indicating wet conditions. Neutral shades around white correspond to near-normal moisture.
We can also do the same with the quarterly aggregated values.
# For region layersdata_map_q <-vector(mode ="list", length =4)for (i in1:4) { data_map_q[[i]] <- maps_level_1_NZ |>inner_join( region_weather_quarterly |>filter(year ==2013, quarter ==!!i),by =c("GID_1", "NAME_1"="region") )}data_map_q <-list_rbind(data_map_q) |>st_as_sf()# For cell layersdata_map_q_cells <-vector(mode ="list", length =4)for (i in1:4) { data_map_q_cells[[i]] <- cells_sf |>inner_join( country_weather_quarterly |>filter(year ==2013, quarter ==!!i),by =c("cell_id", "longitude", "latitude") )}data_map_q_cells <-list_rbind(data_map_q_cells) |>st_as_sf()
This time, we define a small function to create the plots, plot_maps_q(). There is no real point to do so, we just want to provide a second alternative.
The plot_maps_q() function.
#' Maps for each month for a variable showing temperaturesplot_maps_q <-function(var_temp_name, legend_title,geo =c("cell", "region"),legend_type =c("precip", "temp", "drought")) { geo <-match.arg(geo) legend_type <-match.arg(legend_type) df_plot <-if (geo =="cell") data_map_q_cells else data_map_q p <-ggplot() +geom_sf(data = df_plot,mapping =aes(fill =!!sym(var_temp_name)) ) +facet_wrap(~ quarter, ncol =4) +theme_map_paper() +theme(legend.position ="bottom", legend.key.height =unit(1, "line")) p <-switch( legend_type,"temp"= p +scale_fill_gradientn(name = legend_title,colours = cols,limits =c(vmin, vmax),oob = scales::squish ),"precip"= p +scale_fill_gradient2(name = legend_title,low ="red", high ="#005A8B", midpoint =0, mid ="white" ),"drought"= p +scale_fill_gradientn(name = legend_title,colours = cols_smdi,limits =c(-4, 4),oob = scales::squish ) )if (geo =="cell") { p <- p +geom_sf(data = maps_level_1_NZ, fill ="NA") +coord_sf(xlim =c(bb["xmin"], bb["xmax"]),ylim =c(bb["ymin"], bb["ymax"]),expand =FALSE ) } p}
Having this function would allow to quickly loop over the different variables and plot maps. We do not do it in this notebook.
# This chunk is not evaluatedconfigs_maps <-tribble(~variable, ~title, ~type,"precip", "Precip. (mm)", "precip","temp_mean", "Temperature Mean (°C)", "temp","temp_min", "Temperature Min (°C)", "temp","temp_max", "Temperature Max (°C)", "temp","SMDI_month", "SMDI", "drought","SPEI_3", "SPEI-3", "drought",) |>expand_grid(geo =c("region", "cell"))for (i in1:nrow(configs_maps)) {plot_maps_q(var_temp_name = configs_maps$variable[i], legend_title = configs_maps$title[i], geo = configs_maps$geo[i], legend_type = configs_maps$type[i] )}
In our context, we assume that weather shocks primarily affect the agricultural sector, before propagating to the broader economy. Consequently, when aggregating weather variables at the national level, we apply weights that capture the relative agricultural intensity of each region. By doing so, areas where agriculture plays a larger economic role contribute more to the national weather indices.
Important
If one wishes to perform the aggregation in a different context, these weights should be adapted accordingly. Setting all weights to 1 would correspond to a simple unweighted average, implicitly assuming that each grid cell contributes equally to national exposure. Such an assumption may overlook important spatial heterogeneity in sectoral relevance.
5.6.2.1 Regional Agricultural Intensity
To aggregate grid-cell weather measures to the national level in a way that reflects sectoral exposure, we build regional agricultural weights from regional accounts.
Statistics New Zealand’s regional GDP by industry (series RNA001AA) is downloaded from Infoshare (CSV export; the Excel export uses locale-dependent thousand separators that break on our French setup). Our extract covers 2000–2023 by region. We target a working sample of 1987–2024, so we must extrapolate outside the extract window: 1987–1999 (backward) and 2024 (forward).
5.6.2.1.1 Extrapolation strategy
Let \(Y^{(a)}_{r,t}\) denote agricultural GDP for region \(r\) and year \(t\).
We compute the inverse growth rate: \[
\Delta_{r,t}^{-1} = \frac{Y^{(a)}_{r,t}}{Y^{(a)}_{r,t+1}},
\tag{5.21}\] defined wherever both years \(t\) and \(t+1\) are observed.
Over a reference window of width equal to the number of observed years minus 1 (because the computation of \(\Delta_{r,t}^{-1}\) make us lose an observation), hence corresponding to the observed period, we estimate a linear trend in \(\Delta_{r,t}^{-1}\): \[
\Delta_{r,t}^{-1} = \alpha_r + \beta_r \cdot t + \varepsilon_{r,t},
\tag{5.22}\] and retain \(\hat\beta_r\).
For backward fills (years preceding the extract), we form a geometrically weighted average of the windowed inverse growth rates and blend it 50/50 with the trend-implied growth: \[
\widehat{\gamma}_{r,t}^{\text{back}}
= \tfrac{1}{2}\Big(\sum_{j=1}^{W} w_j \Delta_{r,t+j}^{-1}\Big)
+ \tfrac{1}{2}\big(1 + \hat\beta_r\big),
\tag{5.23}\] where \(w_j \propto \text{reason}^{j-1}\) with \(\text{reason}=1/1.35\) and \(\sum_j w_j=1\).
We then impute \[
Y^{(a)}_{r,t} = \widehat{\gamma}_{r,t}^{\text{back}} \times \Delta_{r,t+1}^{-1}.
\tag{5.24}\]
For forward fills (years after the extract), we apply the trend growth: \[
\Delta_{r,t}^{-1} = \Delta_{r,t-1}^{-1} \times \big(1+\hat\beta_r\big).
\tag{5.25}\]
This approach borrows strength from the local history (via the weighted window) while guarding against short-run noise (via the trend).
5.6.2.1.2 Weight construction
Let \(Y^{(a)}_{t}\) be the national agricultural GDP. For each region \(r\) and year \(t\), we define the agricultural intensity weight as follows:: \[
w_{r,t} = \frac{Y^{(a)}_{r,t}}{Y^{(a)}_{t}}.
\tag{5.26}\] By construction, \(\sum_{r} w_{r,t} = 1\) for each year \(t\) (up to rounding). These weights can then be used to aggregate weather variables from regions to the national level..
Important
Other methods to estimate the regional agricultural intensity can be used. We just present this one.
5.6.2.1.3 Implementation in R
Let us compute these weights in R now. We first load the dataset:
New names:
Rows: 24 Columns: 19
── Column specification
──────────────────────────────────────────────────────── Delimiter: "," dbl
(19): ...1, Northland, Auckland, Waikato, Bay of Plenty, Gisborne, Hawke...
ℹ Use `spec()` to retrieve the full column specification for this data. ℹ
Specify the column types or set `show_col_types = FALSE` to quiet this message.
• `` -> `...1`
Each column in the table gives the agricultural GDP of a region. For convenience, we pivot the table so that the GDP values are in a single column (that we name gdp_a); another column, region, will indicate the region the values refer to. Once we have pivoted the table, we compute the inverted growth rate for each region.
And we extend the dataset with the desired missing years:
agri <-crossing(year =seq(min(years_to_complete_back), max(years_to_complete_forw)), region =unique(agri$region)) |>full_join( agri, by =c("year", "region") )agri
# A tibble: 702 × 4
year region gdp_a inv_growth_rate
<dbl> <chr> <dbl> <dbl>
1 1987 Auckland NA NA
2 1987 Bay of Plenty NA NA
3 1987 Canterbury NA NA
4 1987 Gisborne NA NA
5 1987 Hawke's Bay NA NA
6 1987 Manawatu-Whanganui NA NA
7 1987 Marlborough NA NA
8 1987 New Zealand NA NA
9 1987 Northland NA NA
10 1987 Otago NA NA
# ℹ 692 more rows
For each region \(r\), we regress the inverse growth rate \(\Delta_{r,t}^{-1}\) on a linear trend (see Equation 5.22) and return the coefficient associated with the trend, \(\hat\beta_r\):
# Regression of agricultural production on the ref. period on a linear trend# Extraction of the coefficientcoefs <- agri |>filter(year %in% years_reference) |>group_by(region) |>mutate(t =row_number()) |>group_modify(~ { model <-lm(inv_growth_rate ~ t, data = .x)tibble(coef_t =coef(model)[["t"]]) })
As explained in Equation 5.23, we set some weights \(w_j\) to compute a geometrically weighted average of the inverse growth rate.
Then, we loop on each region \(r\) to impute the missing values for agricultural GDP \(Y^{(a)}_{r,t}\).
for (region inunique(agri$region)) {# Focus on curent region coef_region <- coefs |>filter(region ==!!region) |>pull(coef_t)## Predict backward ----for (i in1:length(years_to_complete_back)) { year <- years_to_complete_back[i] ind_row <-which(agri$year == year & agri$region == region) ind_row_next <-which(agri$year == year+1& agri$region == region) window <-seq(year +1, year + width) agri_region_w <- agri |>filter(region ==!!region, year %in%!!window)# Agricultural GDP in the next year gdp_a_next <- agri$gdp_a[ind_row_next]# Complete missing values agri$gdp_a[ind_row] <- ((.5*(pond %*% agri_region_w$inv_growth_rate)) + (.5*(1+coef_region))) * gdp_a_next agri$inv_growth_rate[ind_row] <- agri$gdp_a[ind_row] / agri$gdp_a[ind_row_next] }## Predict forward ----for (i in1:length(years_to_complete_forw)) { year <- years_to_complete_forw[i] ind_row <-which(agri$year == year & agri$region == region) ind_row_prev <-which(agri$year == year-1& agri$region == region)# Previous agricultural GDP gdp_a_previous <- agri$gdp_a[ind_row_prev]# Prediction assuming the linear trend agri$gdp_a[ind_row] <- gdp_a_previous * (1+coef_region) }}
We can compute the regional weights \(w_{r,t}\) (Equation 5.26).
# Expressing as a share of total national valuetb_agri_shares <- agri |>filter(!region =="Nez Zealand") |>group_by(year) |>mutate(agri_share_region = gdp_a /sum(gdp_a))tb_agri_shares |>select(year, region, gdp_a, agri_share_region)
# A tibble: 702 × 4
# Groups: year [39]
year region gdp_a agri_share_region
<dbl> <chr> <dbl> <dbl>
1 1987 Auckland 180. 0.0133
2 1987 Bay of Plenty 350. 0.0259
3 1987 Canterbury 605. 0.0448
4 1987 Gisborne 84.6 0.00626
5 1987 Hawke's Bay 291. 0.0215
6 1987 Manawatu-Whanganui 446. 0.0330
7 1987 Marlborough 73.5 0.00544
8 1987 New Zealand 4470. 0.331
9 1987 Northland 303. 0.0224
10 1987 Otago 289. 0.0214
# ℹ 692 more rows
5.6.2.2 Matching Regional Agricultural Intensity and Weather Data
5.6.2.2.1 Quick Fix on Region Names
Region names often differ across sources. Here, we need to align agricultural intensity (from a national source) with weather data whose regions follow GADM names.
First, we list weather regions that do not appear in the agricultural data:
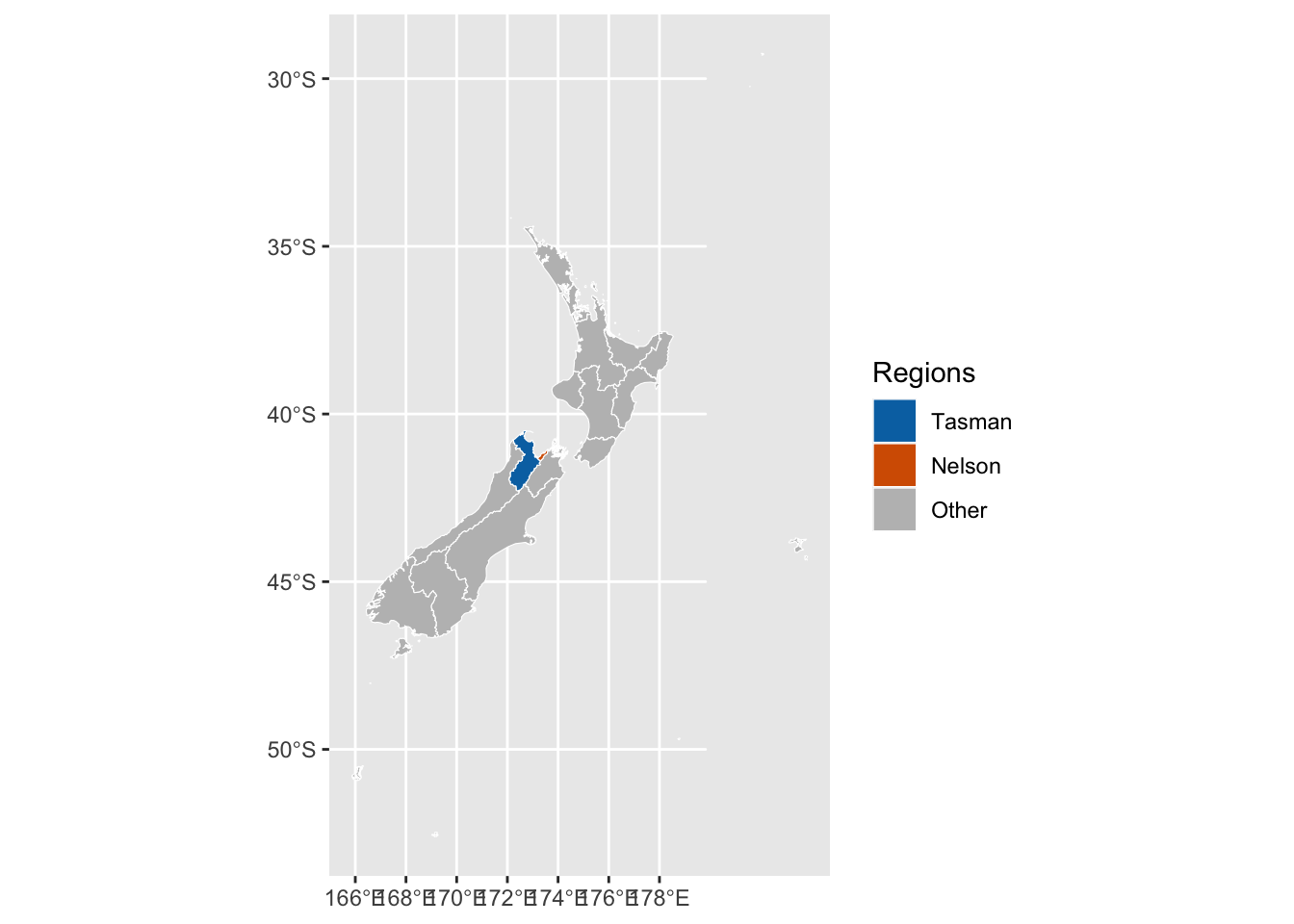
Figure 5.30: Regions merged in the agricultural data.
Tasman is much larger than Nelson, so we split the combined agricultural share proportionally to their land areas (not 50/50). We compute areas from the map.
# Areas of each regionnz_areas <- maps_level_1_NZ |>filter(NAME_1 %in%c("Tasman", "Nelson")) |>mutate(area_m2 =st_area(geometry)) |>st_drop_geometry() |>mutate(area_m2 =as.numeric(area_m2)) |>select(region = NAME_1, area_m2)nz_areas
region area_m2
1 Nelson 419763011
2 Tasman 9631754767
Now we duplicate each "Tasman/Nelson" row into two rows ("Tasman" and Nelson) and allocate gdp_a and agri_share_region using the weights:
group_label <-"Tasman/Nelson"tb_agri_shares <-# keep all rows that are not the Tasman + Nelson aggregate tb_agri_shares |>filter(region !=!!group_label) |>bind_rows(# duplicate the grouped rows for Tasman and Nelson and split the share tb_agri_shares |>filter(region ==!!group_label) |># create two copies per row, one for each regioncrossing(region_2 =c("Tasman", "Nelson")) |>select(-region) |>rename(region = region_2) |># add area weightsleft_join(tas_nel_weights, by ="region") |># apportion only the agri_share_region (as asked)mutate(gdp_a = gdp_a * w,agri_share_region = agri_share_region * w) |>select(-w) ) |>arrange(region, year)
As a sanity check, we look whether weather regions are still missing from the agricultural table:
To obtain national-level indicators, we aggregate regional weather observations using agricultural intensity as weights. We merge the regional weather data with the corresponding agricultural weights (from agri_share_region) for each year and compute the weighted mean of each weather variable.
For monthly data, we group by year and month:
national_weather_monthly <- region_weather_monthly |># We restricted the agricultural data to 1987--2024filter(year >=1987) |>left_join( tb_agri_shares |>select(year, region, agri_share_region),by =c("region", "year") ) |>group_by(year, month, month_name) |>summarise(across(all_of(weather_vars),~weighted.mean(.x, w = agri_share_region) ),.groups ="drop" )
For quarterly data, the same logic applies, except we aggregate by year and quarter:
national_weather_quarterly <- region_weather_quarterly |># We restricted the agricultural data to 1987--2024filter(year >=1987) |>left_join( tb_agri_shares |>select(year, region, agri_share_region),by =c("region", "year") ) |>group_by(year, quarter) |>summarise(across(all_of(weather_vars),~weighted.mean(.x, w = agri_share_region) ),.groups ="drop" )
We can have a look at the obtained values using different type of plots.
Codes to create the Figure.
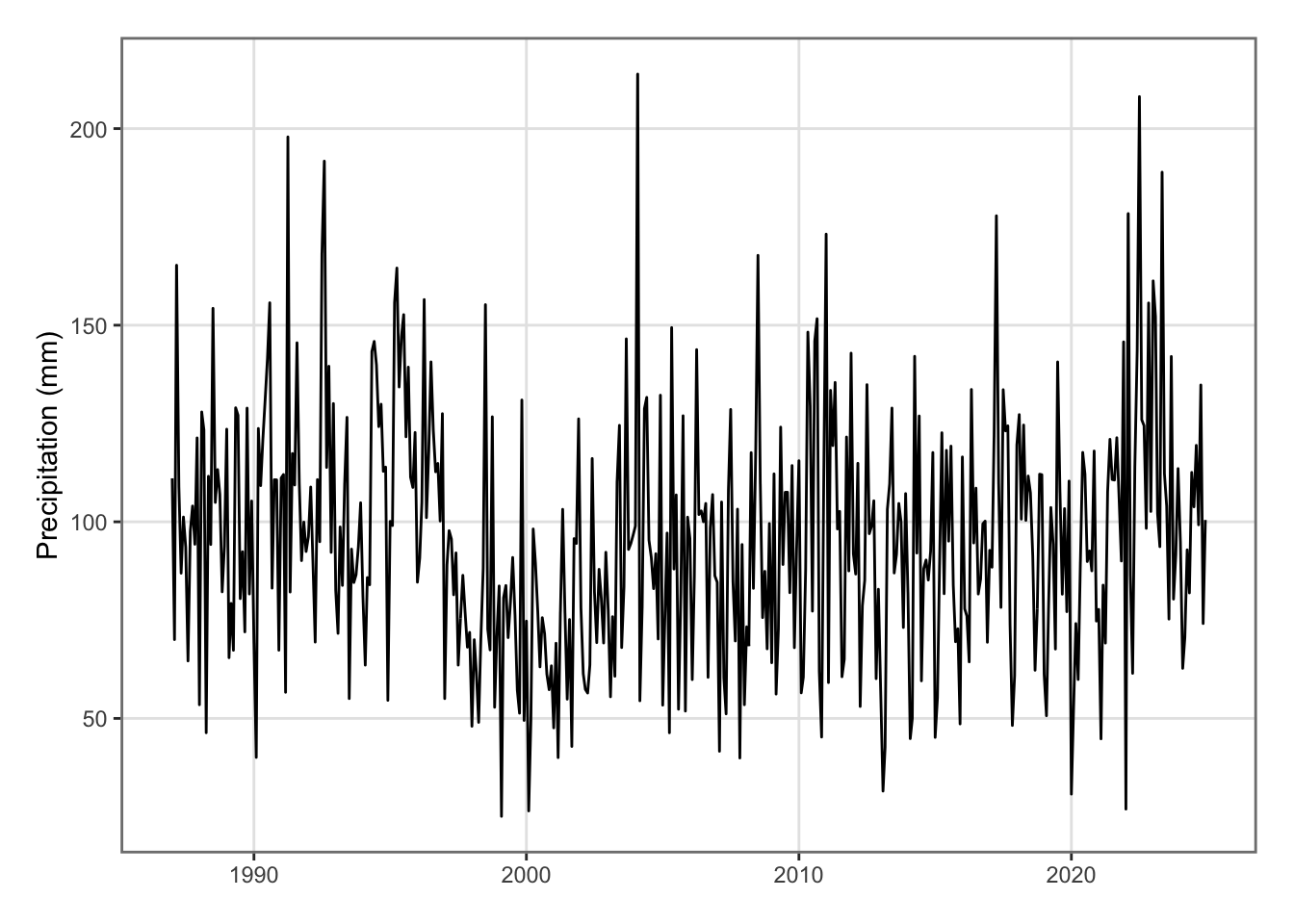
ggplot(data = national_weather_monthly |>mutate(date =make_date(year, month)),mapping =aes(x = date, y = precip)) +geom_line() +labs(x =NULL, y ="Precipitation (mm)") +theme_paper()
Figure 5.31: Precipitation in New Zealand on a monthly basis.
With the quarterly national aggregation:
Codes to create the Figure.
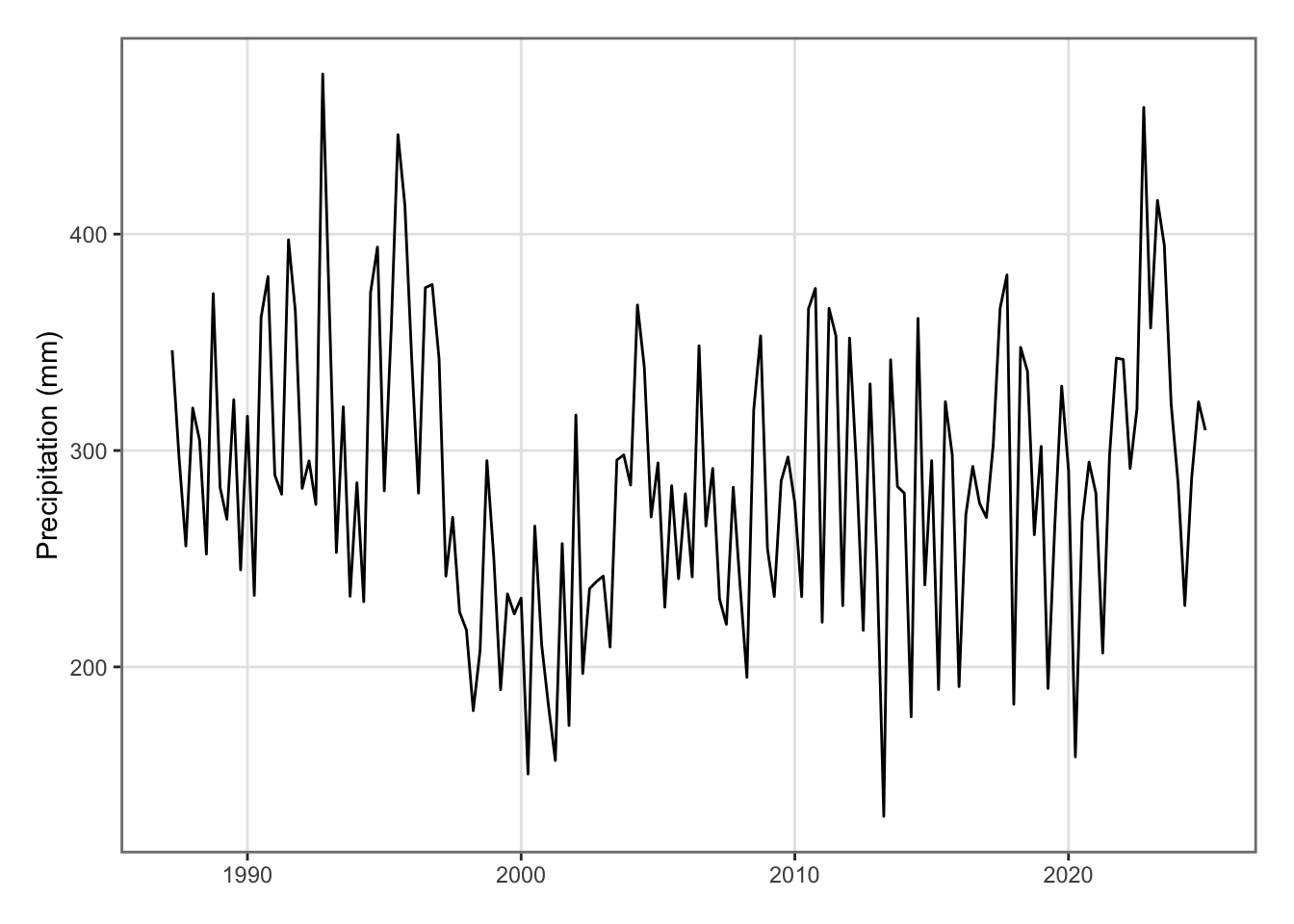
ggplot(data = national_weather_quarterly |>mutate(date = year + quarter/4),mapping =aes(x = date, y = precip)) +geom_line() +labs(x =NULL, y ="Precipitation (mm)") +theme_paper()
Figure 5.32: Precipitation in New Zealand on a quarterly basis.
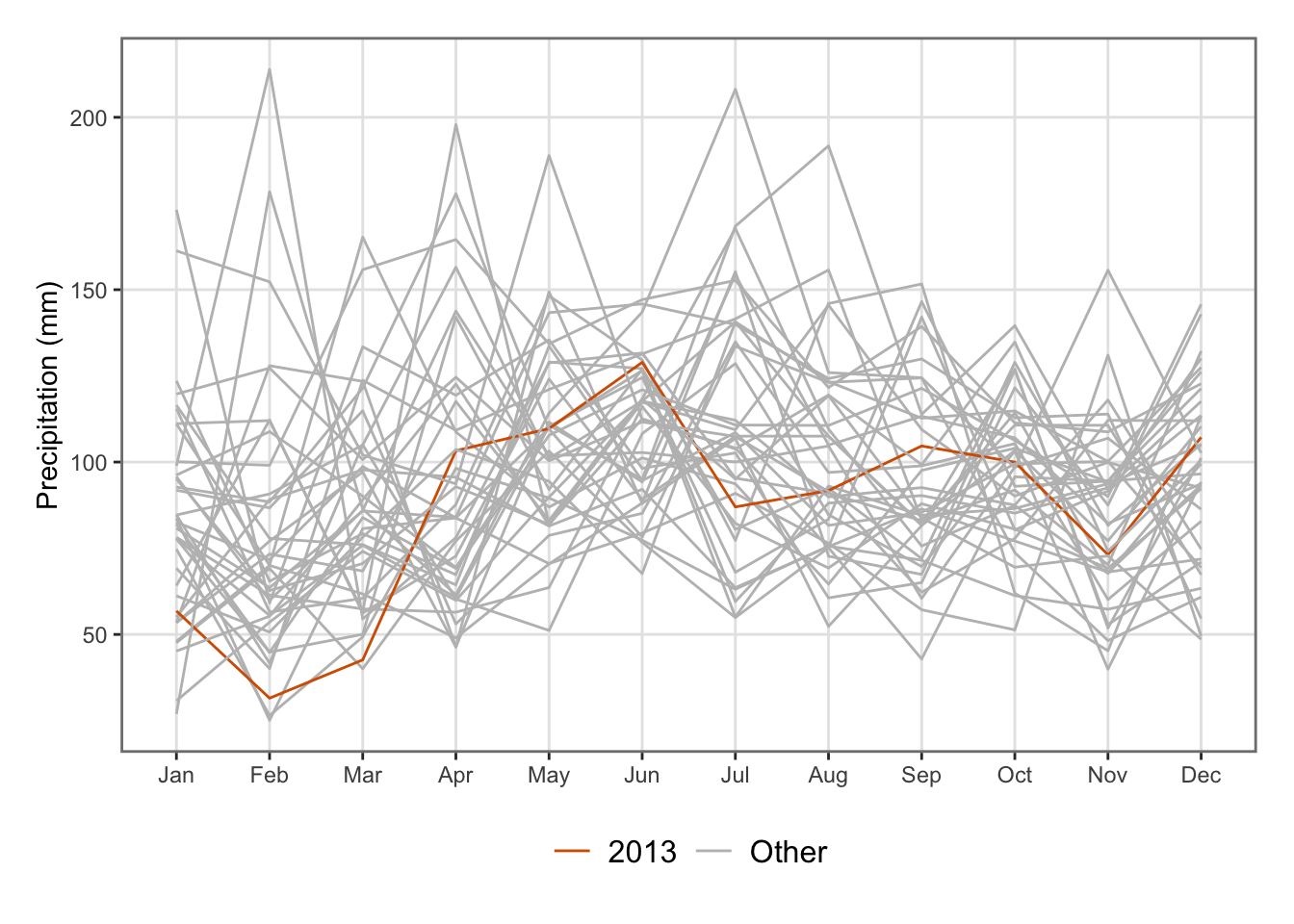
If one wants to highlight a specific year, e.g., 2013:
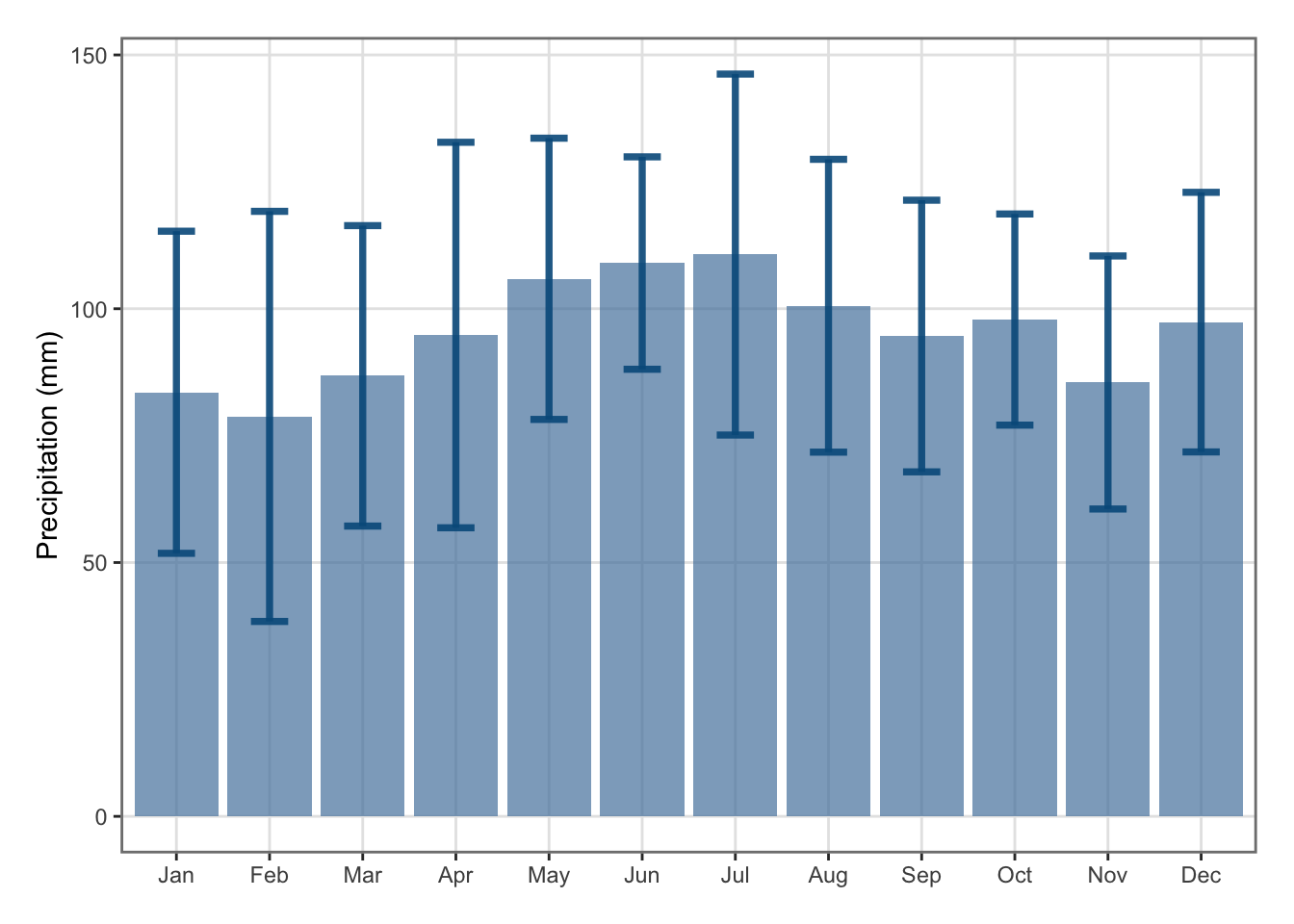
Figure 5.34: Barplot of precipitation in New Zealand on a monthly basis (1987–2024).
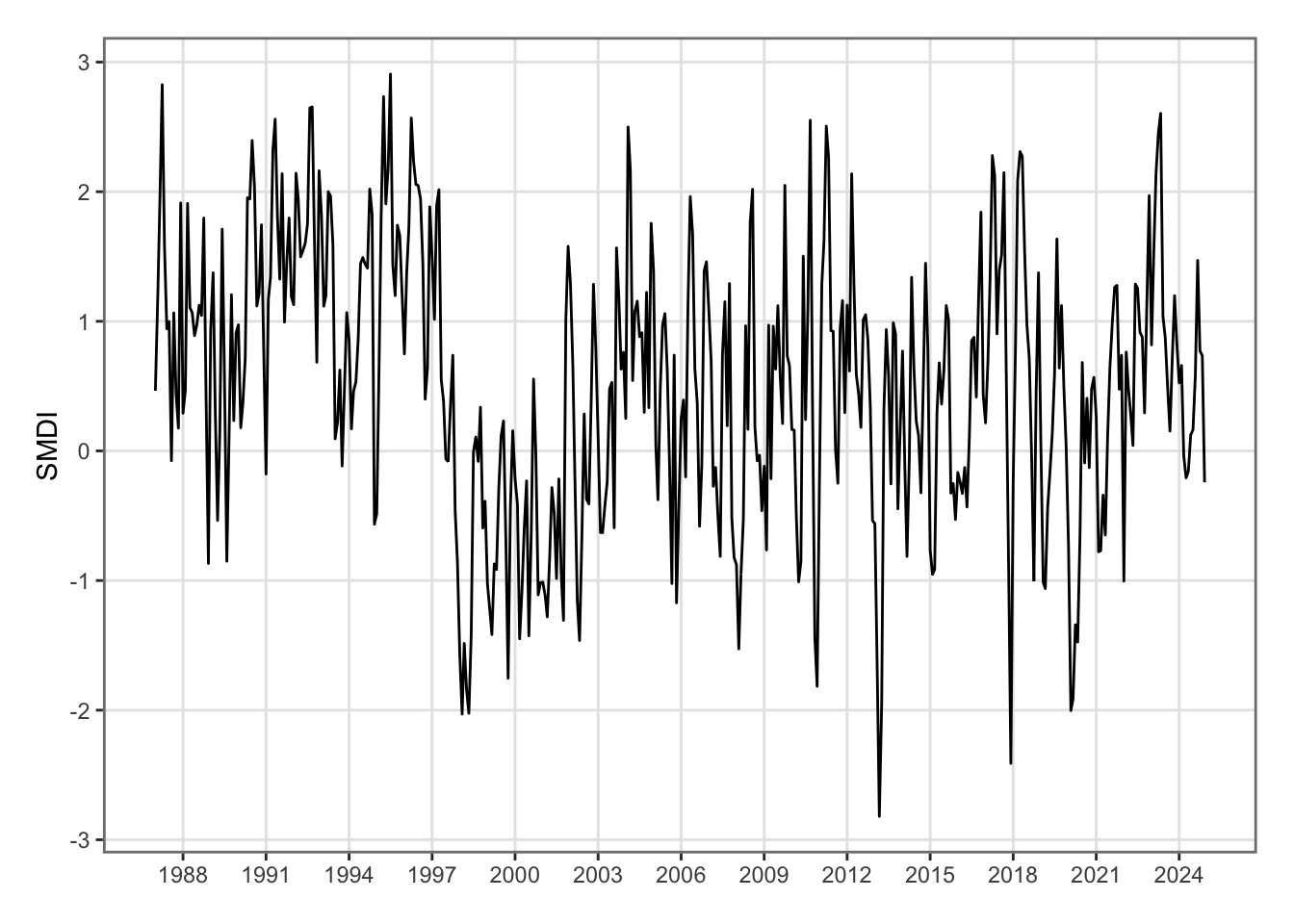
Obviously, we are not restricted to plots showing temperatures. Let us visualize the evolution of the SMDI between 1987 and 2024, on a monthly basis. Note that the spatial aggregation has flattened the series (recall the monthly values before spatial aggregation range between -4 (very dry) to +4 (very wet)).
Figure 5.35: Soil Moisture Deficit Index in New Zealand, monthly basis.
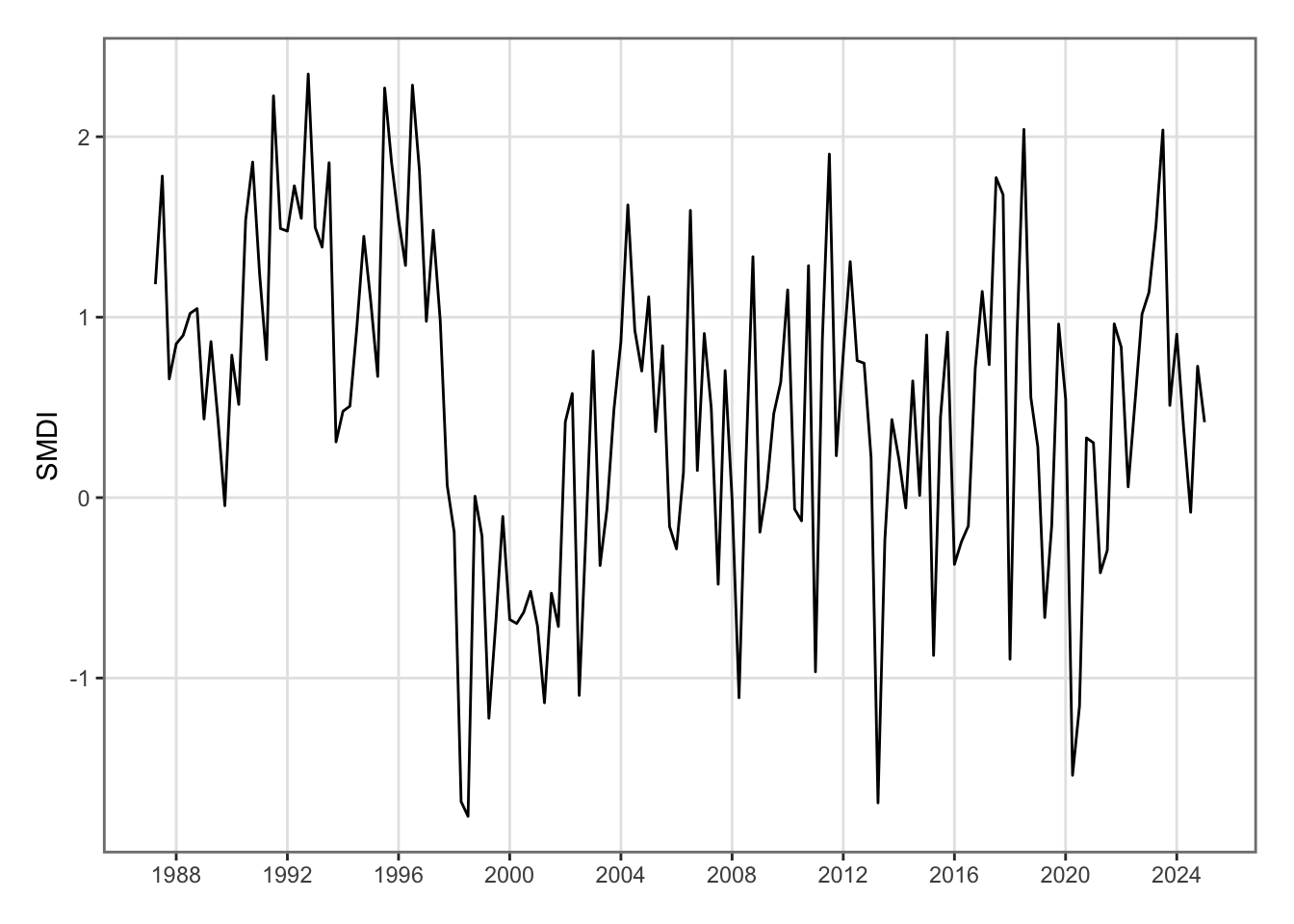
And with the quarterly data:
Codes to create the Figure.
ggplot(data = national_weather_quarterly |>mutate(date = year + quarter/4),mapping =aes(x = date, y = SMDI)) +geom_line() +scale_x_continuous(n.breaks =12) +labs(x =NULL, y ="SMDI") +theme_paper()
Figure 5.36: Soil Moisture Deficit Index in New Zealand, quarterly basis.
5.7 Saving the Datasets
To finish, let us export the two datasets. If those datasets are to be used in R later on, they can be saved as RData files to save space and importing time.
Table 5.2: Dictionary of variables for monthly precipitation (national_weather_monthly)
Variable
Type
Description
year
numeric
Year
month
numeric
Month
month_name
ordered factor
Name of the month
precip
numeric
Average of monthly precipitation (mm)
temp_min
numeric
Average of monthly min temperature (°C)
temp_max
numeric
Average of monthly max temperature (°C)
temp_mean
numeric
Average of monthly mean temperature (°C)
SMDI
numeric
Soil Moisture Deficit Inded (from -4, very dry to +4n very wet)
SPEI_1
numeric
1-Month Standardised Precipitation-Evapotranspiration Index with (negative values for dry, positive for wet)
SPEI_3
numeric
3-Months Standardised Precipitation-Evapotranspiration Index with (negative values for dry, positive for wet)
SPEI_6
numeric
6-Months Standardised Precipitation-Evapotranspiration Index with (negative values for dry, positive for wet)
SPEI_12
numeric
12-Months Standardised Precipitation-Evapotranspiration Index with (negative values for dry, positive for wet)
Table 5.3: Dictionary of variables for quarterly precipitation (national_weather_quarterly)
Variable
Type
Description
year
numeric
Year
quarter
numeric
Quarter
month_name
ordered factor
Name of the month
precip
numeric
Average of monthly precipitation (mm)
temp_min
numeric
Average of monthly min temperature (°C)
temp_max
numeric
Average of monthly max temperature (°C)
temp_mean
numeric
Average of monthly mean temperature (°C)
SMDI
numeric
Soil Moisture Deficit Inded (from -4, very dry to +4n very wet)
SPEI_1
numeric
1-Month Standardised Precipitation-Evapotranspiration Index with (negative values for dry, positive for wet)
SPEI_3
numeric
3-Months Standardised Precipitation-Evapotranspiration Index with (negative values for dry, positive for wet)
SPEI_6
numeric
6-Months Standardised Precipitation-Evapotranspiration Index with (negative values for dry, positive for wet)
SPEI_12
numeric
12-Months Standardised Precipitation-Evapotranspiration Index with (negative values for dry, positive for wet)
Campbell, Gaylon S., and John M. Norman. 1998. “Introduction.” In An Introduction to Environmental Biophysics, 1–13. Springer New York. https://doi.org/10.1007/978-1-4612-1626-1_1.
Dingman, S. Lawrence. 2015. Physical Hydrology. Waveland press.
Hamon, W. R. 1964. “Computation of Direct Runoff Amounts from Storm Rainfall” 63: 52–62.
Lutz, James A., Jan W. van Wagtendonk, and Jerry F. Franklin. 2010. “Climatic Water Deficit, Tree Species Ranges, and Climate Change in Yosemite National Park.”Journal of Biogeography 37 (5): 936–50. https://doi.org/10.1111/j.1365-2699.2009.02268.x.
Narasimhan, B., and R. Srinivasan. 2005. “Development and Evaluation of Soil Moisture Deficit Index (SMDI) and Evapotranspiration Deficit Index (ETDI) for Agricultural Drought Monitoring.”Agricultural and Forest Meteorology 133 (1–4): 69–88. https://doi.org/10.1016/j.agrformet.2005.07.012.
Vicente-Serrano, Sergio M., Santiago Beguería, and Juan I. López-Moreno. 2010. “A Multiscalar Drought Index Sensitive to Global Warming: The Standardized Precipitation Evapotranspiration Index.”Journal of Climate 23 (7): 1696–1718. https://doi.org/10.1175/2009jcli2909.1.