This chapter uses Jordà (2005) Local Projection framework to measure how sensitive agricultural output is to exogenous changes in the weather. Instead of using monthly data as in Chapter 7, we use here annual data.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(fastDummies)
Thank you for using fastDummies!
To acknowledge our work, please cite the package:
Kaplan, J. & Schlegel, B. (2023). fastDummies: Fast Creation of Dummy (Binary) Columns and Rows from Categorical Variables. Version 1.7.1. URL: https://github.com/jacobkap/fastDummies, https://jacobkap.github.io/fastDummies/.
# Functions useful to shape the data for local projectionssource("../weatherperu/R/format_data-annual.R")# Load function in utilssource("../weatherperu/R/utils.R")# Load detrending functionssource("../weatherperu/R/detrending-annual.R")
14.1 Linear Local Projections
In this section, we focus on estimating the Local Projections (Jordà 2005) to quantify the impact of weather on annual agricultural production. We use panel data, similar to the approach used in the study by Acevedo et al. (2020), and independently estimate models for each specific crop.
For a particular crop denoted as \(c\), the model can be expressed as follows: \[
\begin{aligned}
\underbrace{y_{c,i,{\color{wongGold}t+h}}}_{\text{Production}} = & {\color{wongOrange}\beta_{c,{\color{wongGold}h}}^{{\color{wongPurple}T}}} {\color{wongPurple}{T_{i,{\color{wongGold}t}}}} + {\color{wongOrange}\beta_{c,{\color{wongGold}h}}^{{\color{wongPurple}P}}} {\color{wongPurple}P_{i,{\color{wongGold}t}}}\\
&+\delta_{c,i,h}\underbrace{X_{t}}_{\text{controls}} + \underbrace{\zeta_{c,i,h} \text{Trend}_{t} \times \text{Month}_t + \eta_{c,i,h} \text{Trend}^2_{t} \times \text{Month}_t}_{\text{regional trend}}+\varepsilon_{c,i,t+h}
\end{aligned}
\tag{14.1}\]
Here, \(i\) represents the region, \(t\) represents the time, and \(h\) represents the horizon. The primary focus lies on estimating the coefficients associated with temperature and precipitation for different time horizons\(\color{wongGold}h=\{0,1,...,T_{c}\}\)
14.1.1 Functions
To estimate the models, we develop a function, get_data_lp(), that generates the endogenous variable and the regressors for a specific crop, considering a given time horizon. This function is designed to return a list where each element represents the dataset that will be used for estimating the model corresponding to a specific time horizon.
When we call the get_data_lp() function, we check for missing values in the weather data. If missing values are present for a specific region and crop, we keep only the longest consecutive sequence without missing values. To achieve this, we use the two functions defined previously: get_index_longest_non_na() and keep_values_longest_non_na().
#' Get the data in a table for the local projections, for a specific crop#'#' @param df original dataset#' @param horizons number of horizons#' @param y_name name of the exogenous variable#' @param group_name name of the group variable#' @param crop_name name of the crop to focus on#' @param control_names vector of names of the control variables#' @param weather_names vector of names of the weather variables#' @param add_year_fe should columns with annual dummy variables be added?#' Default to `TRUE`#' @param share_geo vector of names of the variables that contain the share of#' each type of geographical pattern. By default `NULL`: no share used#' @param transition_name name of the variable used to define the transition to#' the two states. By default `NULL`#' @param transition_method if transition function, name of the method to use:#' `logistic` or `normal` (default to `NULL`, i.e., no transition)#' @param state_names name of the two states in a vector of characters (only if#' `transition_name` is not `NULL`). First period corresponds to mapped values#' of `transition_name` close to 0, which is for large positive values of#' `transition_name`#' @param gamma logistic growth rate (default to 3, only used if#' `transition_name` is not `NULL`)#' @param other_var_to_keep vector of names of other variables to keep (default#' to `NULL`: no additional vairable kept)#' @export#' @importFrom dplyr filter select mutate sym group_by across rowwise arrange#' slice lead ends_with#' @importFrom fastDummies dummy_cols#' @importFrom stringr str_c str_detectget_data_lp <-function(df, horizons, y_name, group_name, crop_name, control_names, weather_names,add_year_fe =TRUE,share_geo =NULL,transition_name =NULL,transition_method =NULL,state_names =c("planted", "harvested"),gamma =3,other_var_to_keep =NULL) {if (!is.null(share_geo) &!is.null(transition_name)) {stop("You can only use one between share_geo and transition_name") }# Init empty object to return: list of length horizons df_horizons <-vector(mode ="list", length = horizons +1)# Keep only the variables needed df_focus <- df |>filter(product_eng ==!!crop_name) |>select(!!y_name,!!group_name, year, product_eng,!!!control_names,!!!weather_names,!!!share_geo,!!transition_name,!!other_var_to_keep ) |>mutate(!!group_name :=factor(!!sym(group_name)) )# Year dummy fixed-effectsif (add_year_fe) { df_focus <- df_focus |>dummy_cols(select_columns ="year", remove_first_dummy =FALSE) }# For each region, only keep the longest sequence of non NA values found in# the weather variables df_focus <- df_focus |>group_by(region_id) |>mutate(across(.cols =!!weather_names,.fns = keep_values_longest_non_na,.names ="{.col}_keep" ) ) |>rowwise() |>mutate(keep_cols =all(across(ends_with("_keep")))) |>ungroup() |>filter(keep_cols) |>select(-keep_cols, -!!paste0(weather_names, "_keep"))if (!is.null(share_geo)) {# For each geographical type, multiply the weather variables by the share# that the geo. type representsfor(share_geo_type in share_geo) { df_focus <- df_focus |>mutate(across(.cols =!!weather_names,.fns =~ .x *!!sym(share_geo_type),.names =str_c("{.col}_", share_geo_type) ) ) } }if (!is.null(transition_name)) { state_1_name <- state_names[1] state_2_name <- state_names[2]if (transition_method =="logistic") { df_focus <- df_focus |>mutate(fz =logist(!!sym(transition_name), gamma = gamma) ) } elseif (transition_method =="normal") { df_focus <- df_focus |>mutate(fz =pnorm(-!!sym(transition_name)) ) } else {stop("transition method must be either \"losistic\" or \"normal\"") } df_focus <- df_focus |>dummy_cols(group_name, remove_first_dummy =FALSE) ind_dummies_group <-str_detect(colnames(df_focus), str_c(group_name, "_")) dummies_group_name <-colnames(df_focus)[ind_dummies_group]if (add_year_fe) { ind_dummies_year <-str_detect(colnames(df_focus), "^year_") dummies_year_name <-colnames(df_focus)[ind_dummies_year] dummies_group_name <-c(dummies_group_name, dummies_year_name) } df_focus <- df_focus |>mutate(# First regime:across(.cols =c(!!!control_names, !!!weather_names, !!!dummies_group_name),.fns =list(state_1_name =~ (1- fz) * .x,state_2_name =~ fz * .x ),.names ="{fn}_{col}" ) ) |>rename_with(.fn =~str_replace(string = .x, pattern ="state_1_name", replacement = state_1_name),.cols =starts_with("state_1_name") ) |>rename_with(.fn =~str_replace(string = .x, pattern ="state_2_name", replacement = state_2_name),.cols =starts_with("state_2_name") ) } else { df_focus <- df_focus |>dummy_cols(group_name, remove_first_dummy =FALSE) }# Prepare the values for y at t+hfor (h in0:horizons) { df_horizons[[h+1]] <- df_focus |>group_by(!!sym(group_name)) |>arrange(year) |>mutate(time =row_number()) |>mutate(y_lead = dplyr::lead(!!sym(y_name), n = h)) |>slice(1:(n()-h)) }names(df_horizons) <-0:horizons df_horizons}
Following the data preparation step, we proceed to define a function, estimate_linear_lp() that performs the estimation of models for all time horizons. This function used the datasets obtained through the get_data_lp() function.
#' Estimate Local Projections#'#' @param df original dataset#' @param horizons number of horizons#' @param y_name name of the exogenous variable#' @param group_name name of the group variable#' @param crop_name name of the crop to focus on#' @param control_names vector of names of the control variables#' @param weather_names vector of names of the weather variables#' @param detrend if `TRUE` a group-wise quadratic temporal effect is estimated#' (group:time + group:I(time^2))#' @param add_year_fe should columns with year dummy variables be added?#' Default to `TRUE`#' @param add_intercept should an intercept we added to the regressions?#' (default to `FALSE`)#' @param share_geo vector of names of the variables that contain the share of#' each type of geographical pattern. By default `NULL`: no share used#' @param std type of standard error (`"NW"` for Newey-West, `"Cluster"`,#' `"Standard"` otherwise)#' @param transition_name name of the variable used to define the transition to#' the two states. By default `NULL`#' @param transition_method if transition function, name of the method to use:#' `logistic` or `normal` (default to `NULL`, i.e., no transition)#' @param state_names name of the two states in a vector of characters (only if#' `transition_name` is not `NULL`). First period corresponds to mapped values#' of `transition_name` close to 0, which is for large positive values of#' `transition_name`#' @param gamma logistic growth rate (default to 3, only used if#' `transition_name` is not `NULL`)#' @param other_var_to_keep vector of names of other variables to keep in the#' returned dataset (default to `NULL`: no additional vairable kept)#' @export#' @importFrom dplyr mutate sym ungroup summarise across left_join#' @importFrom stringr str_c str_detect#' @importFrom purrr map map_dbl list_rbind#' @importFrom tibble enframe#' @importFrom tidyr pivot_longer#' @importFrom sandwich NeweyWest#' @importFrom stats sd model.matrix nobs residuals lm coefestimate_linear_lp <-function(df, horizons, y_name, group_name, crop_name, control_names, weather_names,detrend =FALSE,add_year_fe =TRUE,add_intercept =FALSE,share_geo =NULL,transition_name =NULL,transition_method =NULL,state_names =c("planted", "harvested"),gamma =3,std =c("nw", "cluster", "standard"),other_var_to_keep =NULL) {# Format the dataset data_lp <-get_data_lp(df = df,horizons = horizons,y_name = y_name,group_name = group_name,crop_name = crop_name,control_names = control_names,weather_names = weather_names,share_geo = share_geo,transition_name = transition_name,transition_method = transition_method,state_names = state_names,gamma = gamma,other_var_to_keep = other_var_to_keep )# Recode levels for the groupsfor(h in0:horizons){ data_lp[[h +1]] <- data_lp[[h +1]] |>mutate(!!group_name :=as.factor(as.character(!!sym(group_name))) ) } control_names_full <- control_names weather_names_full <- weather_names ind_names_groups <-str_detect(colnames(data_lp[[1]]), str_c("^", group_name, "_") ) group_names_full <-colnames(data_lp[[1]])[ind_names_groups]if (!is.null(share_geo)) {# Name of the weather variables weather_names_full <-paste(rep(weather_names, each =length(share_geo)), share_geo,sep ="_" ) }if (!is.null(transition_name)) { state_1_name <-str_c(state_names[1], "_") state_2_name <-str_c(state_names[2], "_")# Name of the variables weather_names_full <-str_c(rep(c(state_1_name, state_2_name),each =length(weather_names) ),rep(weather_names, 2) ) control_names_full <-str_c(rep(c(state_1_name, state_2_name),each =length(control_names) ),rep(control_names, 2) ) ind_names_groups <-str_detect(colnames(data_lp[[1]]),str_c("(^", state_1_name, "|", state_2_name, ")", group_name, "_") ) group_names_full <-colnames(data_lp[[1]])[ind_names_groups] }# Observed standard deviations in the data sd_weather_shock <-map(.x = data_lp,.f =~ungroup(.x) |>summarise(across(.cols =c(!!control_names_full, !!weather_names_full, !!share_geo),.fns = sd ) ) ) |>list_rbind(names_to ="horizon") |>pivot_longer(cols =-horizon, names_to ="name", values_to ="std_shock") |>mutate(horizon =as.numeric(horizon))# Observed median value in the data median_weather_shock <-map(.x = data_lp,.f =~ungroup(.x) |>summarise(across(.cols =c(!!control_names_full, !!weather_names_full, !!share_geo),.fns =~quantile(.x, probs = .5) ) ) ) |>list_rbind(names_to ="horizon") |>pivot_longer(cols =-horizon, names_to ="name", values_to ="median_shock") |>mutate(horizon =as.numeric(horizon))# Observed quantile of order 0.05 value in the data q05_weather_shock <-map(.x = data_lp,.f =~ungroup(.x) |>summarise(across(.cols =c(!!control_names_full, !!weather_names_full, !!share_geo),.fns =~quantile(.x, probs = .05) ) ) ) |>list_rbind(names_to ="horizon") |>pivot_longer(cols =-horizon, names_to ="name", values_to ="q05_shock") |>mutate(horizon =as.numeric(horizon))# Observed quantile of order 0.95 value in the data q95_weather_shock <-map(.x = data_lp,.f =~ungroup(.x) |>summarise(across(.cols =c(!!control_names_full, !!weather_names_full, !!share_geo),.fns =~quantile(.x, probs = .95) ) ) ) |>list_rbind(names_to ="horizon") |>pivot_longer(cols =-horizon, names_to ="name", values_to ="q95_shock") |>mutate(horizon =as.numeric(horizon))if (detrend ==TRUE) {# Formula for the regressions formula_lp <-paste0("y_lead"," ~ -1+",# " ~ 1+", # interceptpaste(weather_names_full, collapse =" + ")," + ",paste(control_names_full, collapse =" + ")," + ",paste0(c(paste0(group_names_full, ":time"),paste0(group_names_full, ":I(time^2)") ),collapse =" + " ) ) } else {# Formula for the regressions formula_lp <-paste0("y_lead"," ~ -1+",# " ~ 1+", # interceptpaste(weather_names_full, collapse =" + ")," + ",paste(control_names_full, collapse =" + ")," + ",ifelse( add_intercept,# removing last groupyes =paste(group_names_full[-length(group_names_full)], collapse =" + "),# keeping last groupno =paste(group_names_full, collapse =" + ") ) ) }if (add_year_fe) { names_year_fe <-colnames(data_lp[[1]])[str_detect(colnames(data_lp[[1]]), "^year_[[:digit:]]{4}")] names_year_fe <-str_c(names_year_fe, collapse =" + ") formula_lp <-paste0(formula_lp, " + ", names_year_fe) } empty_res <-vector(mode ="list", length = horizons +1) reg_lp <- empty_res sig_ols <- empty_res log_likelihood <- empty_res mse <- empty_res coefs <- empty_res cl_std <- empty_resfor (h in0:horizons) {# Global assignment... otherwise, errors with coeftest() current_data_h <<- data_lp[[h+1]]# Regression reg_h <-lm(formula = formula_lp, data = current_data_h)# Standard error of the residuals sig_ols_h <-sd(reg_h$residuals)# Log likelihood u_h <- reg_h$residuals log_likelihood_h <-sum(log(1/sqrt(2* pi * sig_ols_h^2) *exp(-u_h^2/ (2* sig_ols_h^2)))) mse_h <-mean(u_h^2) coefs_h <-enframe(coef(reg_h)) |>mutate(horizon = h)if (std =="Cluster") { cl_std_h <-coeftest( reg_h,vcov = vcovCL,cluster =formula(str_c("~", group_name)))[, "Std. Error"] |>enframe() |>mutate(horizon = h) } else { cl_std_h <-enframe(sqrt(diag(vcov(reg_h))), value ="std") |>mutate(horizon = h) }# Store results in lists reg_lp[[h+1]] <- reg_h sig_ols[[h+1]] <- sig_ols_h log_likelihood[[h+1]] <- log_likelihood_h mse[[h+1]] <- mse_h coefs[[h+1]] <- coefs_h cl_std[[h+1]] <- cl_std_h } se_df <-list_rbind(cl_std) |>rename(std = value) coefs <- coefs |>list_rbind() |>left_join(se_df, by =c("horizon", "name")) |>mutate(crop = crop_name,horizon =as.numeric(horizon) ) |>left_join(sd_weather_shock, by =c("horizon", "name")) |>left_join(median_weather_shock, by =c("horizon", "name")) |>left_join(q05_weather_shock, by =c("horizon", "name")) |>left_join(q95_weather_shock, by =c("horizon", "name"))list(# reg_lp = reg_lp,coefs = coefs,horizons = horizons,log_likelihood = log_likelihood |>list_c(),mse = mse |>list_c(),crop_name = crop_name,data_lp = data_lp )}
Note
The get_data_lp() function is defined in the R script saved here: /weatherperu/R/format_data-annual.R. The estimation function, estimate_linear_lp(), is defined in the R script saved here: /weatherperu/R/estimations-annual.R.
source("../weatherperu/R/estimations-annual.R")
14.1.2 Estimation
To loop over the different crops, we can used the map() function. This function enables us to apply the estimate_linear_lp() function to each crop iteratively.
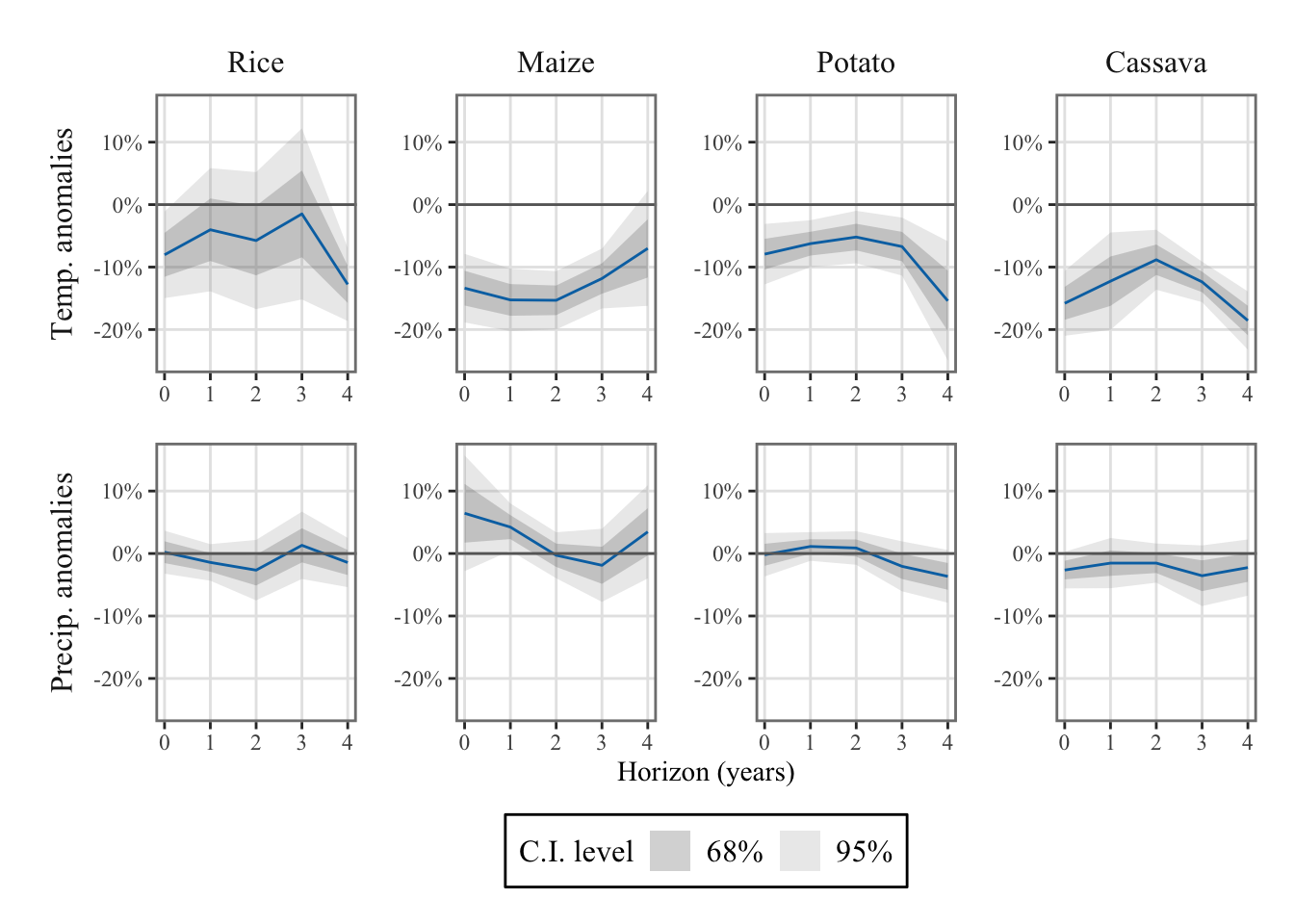
We can visualize the Impulse Response Functions (IRFs) by plotting the estimated coefficients associated with the weather variables. These coefficients represent the impact of weather on agricultural production and can provide valuable insights into the dynamics of the system. By plotting the IRFs, we can gain a better understanding of the relationship between weather variables and the response of agricultural production over time.
Figure 14.1: Agricultural production response to a weather shock
Acevedo, Sebastian, Mico Mrkaic, Natalija Novta, Evgenia Pugacheva, and Petia Topalova. 2020. “The Effects of Weather Shocks on Economic Activity: What Are the Channels of Impact?”Journal of Macroeconomics 65: 103207.
Jordà, Òscar. 2005. “Estimation and Inference of Impulse Responses by Local Projections.”American Economic Review 95 (1): 161–82. https://doi.org/10.1257/0002828053828518.