── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(lubridate)library(sf)
Linking to GEOS 3.11.0, GDAL 3.5.3, PROJ 9.1.0; sf_use_s2() is TRUE
library(rmapshaper)library(raster)
Loading required package: sp
Attaching package: 'raster'
The following object is masked from 'package:dplyr':
select
library(stars)
Loading required package: abind
library(readxl)# install.packages("lwgeom")
4.1.1 Import Data
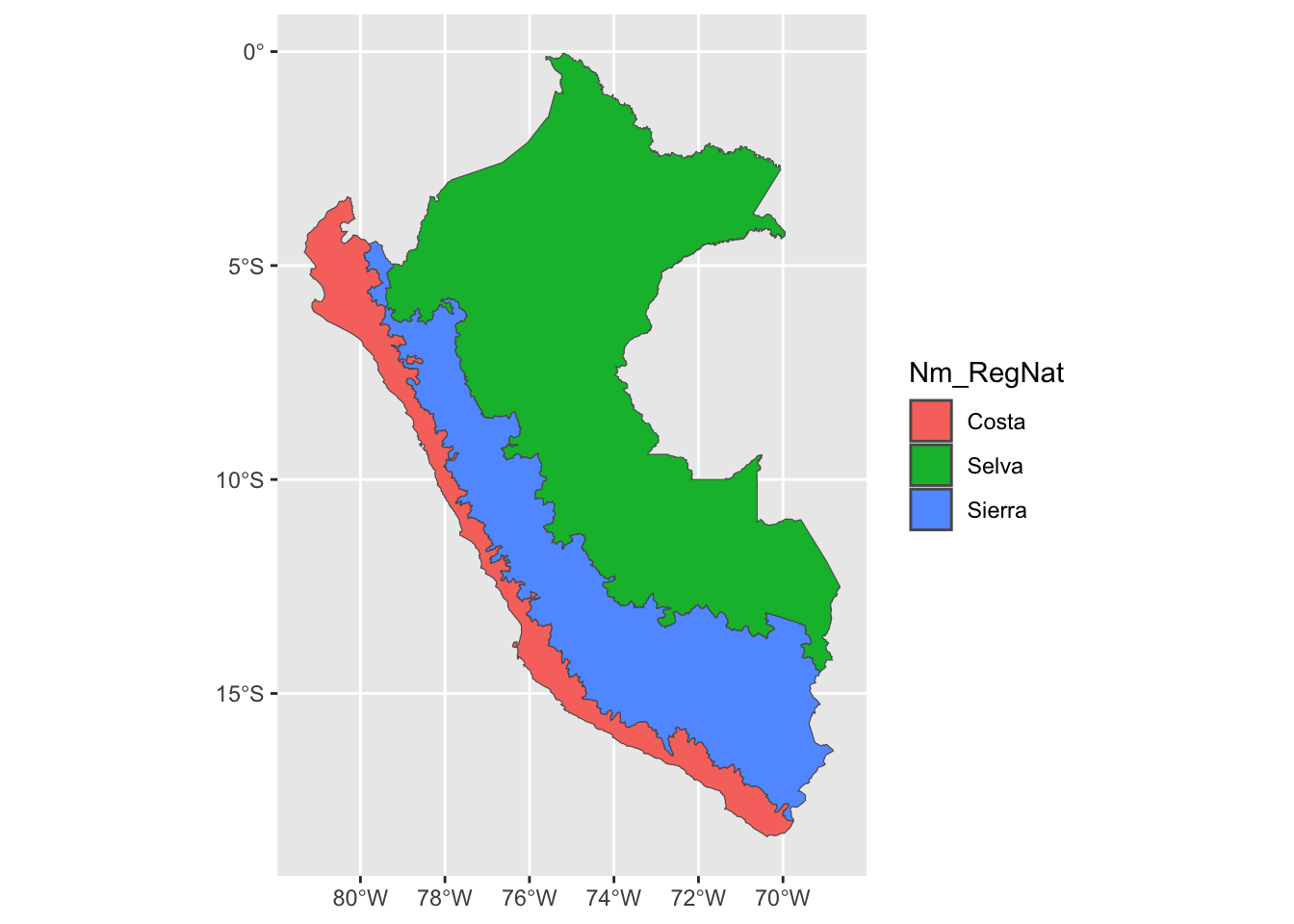
We first import the Peruvian map:
sf::sf_use_s2(FALSE)
Spherical geometry (s2) switched off
# Map of the administrative regions map_peru <- sf::st_read("../data/raw/shapefile_peru/departamentos/", quiet = T)map_peru <- rmapshaper::ms_simplify(input =as(map_peru, 'Spatial')) |>st_as_sf()
Then, we load the map with the definition of the natural regions:
# Map of the natural regions map_regiones_naturales <- sf::st_read(str_c("../data/raw/shapefile_peru/regiones_naturales/","region natural_geogpsperu_JuanPabloSuyoPomalia.geojson" ),quiet = T)
As the file contains a lot of unecessary details, we simplify the polygons:
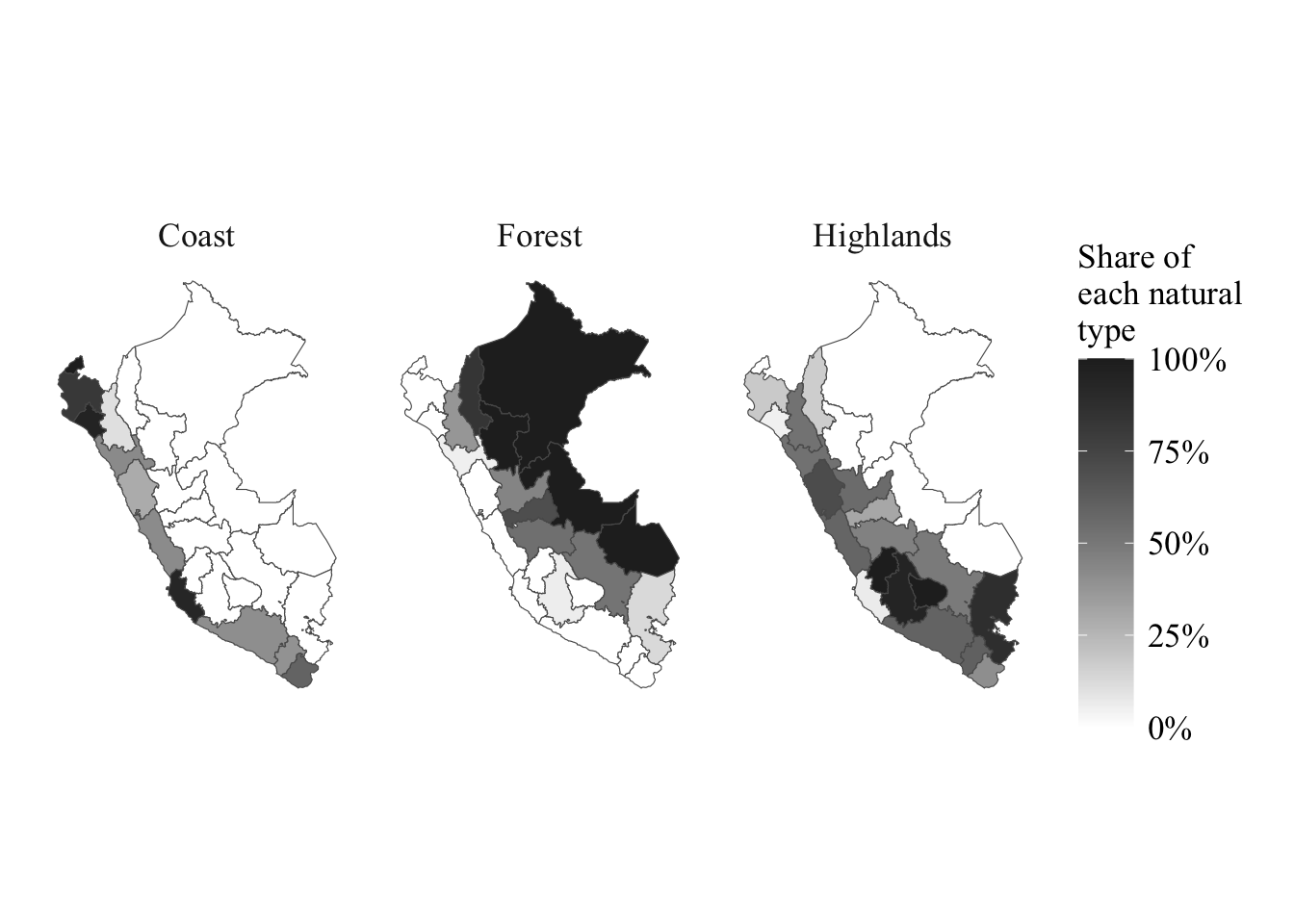
natural_region_dep <- natural_region_dep |> labelled::set_variable_labels(region ="Name of the region",share_costa ="Share of coastal areas in the region",share_selva ="Share of forest areas in the region",share_sierra ="Share of highland areas in the region" )
Table 4.1: Variables in the natural_region_dep file
Variable name
Type
Description
region
character
Administrative Name of the Region
share_sierra
numeric
Share of highlands
share_selva
numeric
Share of forest
share_costa
numeric
Share of coast
5 El Niño–Southern Oscillation
Peru is exposed to the El Niño Southern Oscillation (ENSO) phenomenon. This phenomenon is due to irregular cyclical variations in sea surface temperatures and air pressure of the Pacific Ocean. The ENSO phenomenon is composed of two main phases: the warming phase El Niño, characterized by warmer ocean temperatures in the tropical western Pacific, and the cooling phase La Niña, with a cooling of the ocean surface.
The ENSO variations are classified using the Oceanic Niño Index, which computes a three-months average of the sea surface temperature anomalies in the central and eastern tropical Pacific Ocean. We collect this index from the Golden Gate Weather Service. An El Niño (or La Niña) event is defined by a five consecutive three-months periods with an index above 0.5 (or below -0.5 for a La Niña event).